Apache SOLR es el proyecto de código abierto de referencia para la creación de motores de búsqueda de grado empresarial hecho en Java. En este post veremos el proceso de una búsqueda en SOLR así como las principales funcionalidades y características que hacen de SOLR un potente motor de indexado y búsqueda de contenido, que incluso puede reemplazar al Google Search Appliance – GSA sin despeinarse. Dejaremos para una segunda parte un ejemplo práctico.
Empezaremos con una aplicación de búsqueda “típica” de pisos en alquiler, e iremos viendo el funcionamiento de SOLR pasito a pasito:
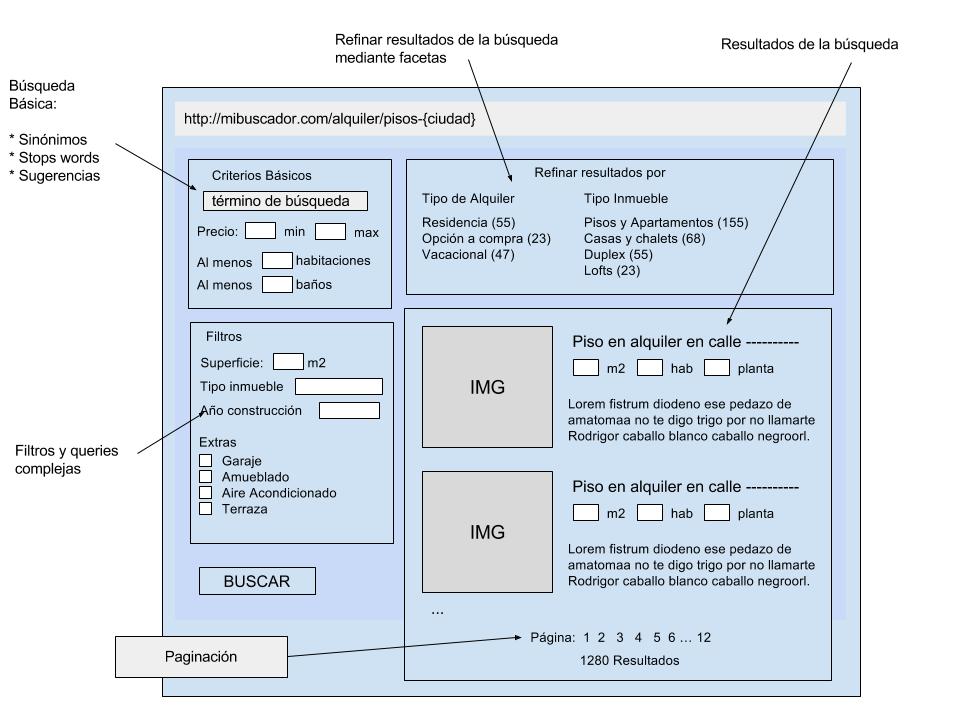
En nuestro buscador, el usuario ingresa un término de búsqueda y esto produce unos resultados que SOLR puede agrupar en categorías y filtrar por otros criterios de búsqueda. A esta funcionalidad de categorizar los resultados se le conoce como “facetado”, siendo cada categoría una faceta. Esto permite que el usuario pueda descubrir nuevos elementos y afinar los resultados de la búsqueda. Para el ejemplo de la imágen, los resultados están facetados por Tipo de Alquiler y Tipo de Inmueble.
Ahora veremos cómo hace SOLR para encontrar coincidencias del término de búsqueda.
Introducción a Apache SOLR
Indexado y búsqueda de documentos
Apache SOLR utiliza como base otro proyecto Java muy popular, Apache Lucene. Lucene es un motor de búsqueda de alto rendimiento y escalable, es potente y tiene multitud de funcionalidades orientadas a la búsqueda.
Resumiendo muy a groso modo, se puede decir que Lucene es una librería para crear y manejar un índice invertido. Este índice invertido es un tipo de estructura de datos especializado para la búsqueda de coincidencias con un término de búsqueda en documentos de texto.
¿Qué es un documento y qué es indexado?
Documento: Un archivo indicando la estructura de los datos a ser procesados. En este archivo se indican: los campos y contenido para cada campo.
Indexado: Es el proceso de añadir documentos a un índice.
Índice: Es una colección o agrupación de documentos indexados.
En la siguiente imagen, veremos mejor cómo funciona este proceso de indexado y búsqueda de documentos:

- Tenemos un documento que queremos indexar. En este punto, SOLR define un identificador interno para el documento, en el ejemplo es el 66.
- El documento a ser indexado, indicando los campos y su contenido.
- Durante el proceso de indexado, cada campo es analizado para identificar términos únicos y sus frecuencias en cada documento.
- En este índice, tenemos un listado de entradas con el ID de cada documento y la frecuencia del término para cada campo del documento. Por ejemplo, “piso” aparece dos veces en el documento con el ID 71.
- Para el término de búsqueda: “san teodoro”, los resultados incluirán los documentos 7, 66, 74, 92 y 102 porque contienen “san” y “teodoro”
Ya hemos visto cómo Lucene procesa y construye el índice de documentos. Pero, ¿cómo sabe SOLR qué indexar del documento que se le está enviando?
Esquema
Apache SOLR permite definir la estructura de nuestro índice de forma declarativa, indicando los campos, tipos de los campos y análisis a utilizar para estos tipos de campos mediante un archivo de esquema. Este archivo de esquema puede variar dependiendo de cómo se haya configurado SOLR y puede ser:
managed-schema: Es el nombre del archivo de esquema utilizado por defecto en SOLR y permite realizar cambios en el esquema “en caliente” a través del Schema API o utilizando el modo Schemaless. Se puede partir de un managed-schema previamente configurado y posteriormente ir añadiendo cambios utilizando la Schema API, siempre y cuando luego de cada cambio en el archivo, se recarge la configuración y se vuelvan a indexar los documentos para aplicar los cambios. El managed-schema es manejado por SOLR a través de una API.
schema.xml : Es el archivo esquema tradicional que puede ser editado manualmente. El schema.xml es manejado por el usuario/administrador de SOLR.
Archivo de configuración Solrconfig.xml
En este archivo podemos configurar dos áreas importantes para el comportamiento y afinamiento de las búsquedas y resultados: request handlers y search components.
Un request handler procesa las solicitudes que llegan a Apache SOLR. Estas solicitudes pueden ser del tipo “request” o “index update”, es decir, para solicitar información o para actualizar documentos del índice.
Dentro de este fichero también podemos configurar los distintos “search components” disponibles en SOLR. Un search component implementa una funcionalidad específica a la búsqueda como el facetado y las sugerencias.
Llegados a este punto, hemos visto que Lucene proporciona un potente motor para indexado de documentos, realizar búsquedas y rankear los resultados. Y que a través del archivo esquema tenemos la facilidad de definir la estructura del índice. Ahora necesitamos una forma de poder acceder a estos servicios.
Apache SOLR: Aplicacion Web Java
Solr es una aplicación Web Java que es la unión de varios componentes, dentro de los cuales podemos resaltar:
- Lucene para indexado y búsqueda.
- Configuración de los componentes y procesadores a través de solrconfig.xml y managed-schema.
- Pipeline de análisis de texto: tokenizadores y filtros (stopwords, sinónimos, lowercase, y más).
- Procesadores de la solicitud de actualización de documentos (index update): utilizados para modificar los campos, incluyendo valores del documento que se está por indexar.
- Componentes de búsqueda (search components): facetas, highlighting, suggester, búsqueda geoespacial y más.
- APIs: para manipulación de cores, colecciones, configuraciones y más.
En la siguiente imagen, veremos a grandes rasgos cómo están alineados estos componentes dentro de SOLR en modo SOLRCloud:
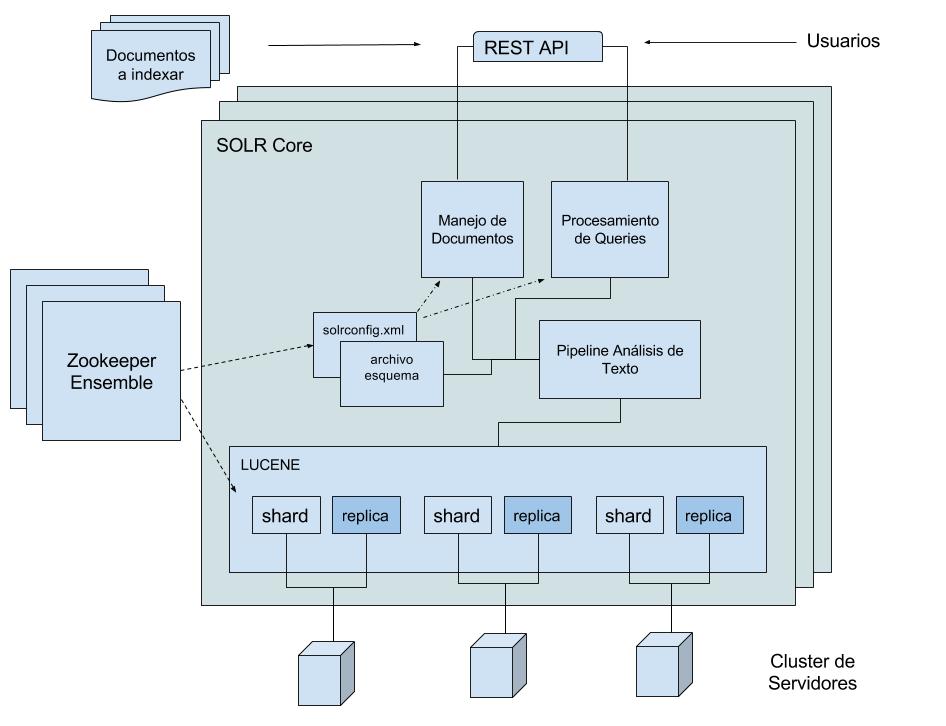
El diagrama es bastante sencillo y permite hacernos una idea general sobre SOLR. Aparecen componentes que aún no hemos mencionado, tranquilos que más adelante sabremos qué son.
SOLR puede ejecutarse en dos modos: un solo servidor y en modo Cloud. Cada uno tiene sus características, terminología y requerimientos, que veremos a continuación.
Diferencias entre SOLR y SOLRCloud
| SOLR | SOLRCloud |
|---|---|
| * Modo un solo servidor. * Indice == Core. * Configuración directamente sobre los archivos de configuración del core. * Recomendado para índices pequeños y donde la escalabilidad / tolerancia a fallos no es un requerimiento. | * Modo distribuido (búsquedas e índices). * Requiere un ensemble de Zookeeper. * Requiere un cluster de SOLR. * Indice == Collection -> Distribuido en Shards * Los shards tienen réplicas * Configuración y administración de los shards a través de Zookeeper. No se hacen modificaciones directamente en SOLR. * APIS para el manejo de configuración, colecciones, y shards. |
Terminología
- Core: Es el término con el que se nombra a un índice cuando SOLR está en modo de un solo servidor.
- Collection: Índice distribuido en shards, cuando SOLR se ejecuta en modo SOLRCloud.
- Shard: Contenedor de una parte del índice, replicado en uno o más servidores para implementar tolerancia a fallos con la ayuda de Zookeeper.
- Apache Zookeeper: Servicio centralizado para distribución de archivos de configuración y sincronización de servicios.
- Zookeeper Ensemble: Cluster de servidores de Zookeeper.
Ya hemos cubierto cómo funciona SOLR, sus componentes, modos de ejecución y hemos descifrado la terminología común. Ahora veremos las características principales que hacen de SOLR una sólida opción para implementar un sistema de búsqueda.
Apache SOLR: Características principales
Extensible
SOLR es modular, permitiendo combinar distintos plugins y componentes para obtener los resultados que necesitamos en los distintos pipelines de datos: previo a indexar un documento, al indexar un documento y durante la búsqueda. Por ejemplo, la combinación de procesadores en un “updateRequestProcessorChain” permite ingresar campos al esquema que no han sido definidos previamente.
Escalable y distribuido
Cuando Apache SOLR se ejecuta en modo SOLRCloud, permite distribuir los documentos de un índice en shards. Para entender mejor qué es un shard, se puede hacer la siguiente analogía: un índice sería como un directorio y si este directorio lo dividimos en secciones, cada sección sería un Shard. La unión del contenido “repartido” (léase distribuido) entre los Shards nos da el índice.
Tolerancia a fallos
Gracias a Zookeeper, si perdemos uno de los servidores donde tenemos uno de nuestros shards, ya sea que hemos configurado previamente un factor de replicación o añadido manualmente réplicas a los shards, Zookeeper verá que uno de nuestros shards está en fallo y automáticamente elegirá un nuevo “leader” para el shard con problemas.

Conclusiones
Cubrir todo Apache SOLR en un artículo es complicado, por eso hemos ido por partes al ver cómo SOLR procesa una búsqueda, su funcionamiento y principales características.
También hemos visto que la configuración en modo SOLRCloud tiene requerimientos especiales que permiten sacarle más rendimiento a Apache SOLR, a la vez que ganamos en escalabilidad y tolerancia a los fallos.
Vale la pena mencionar Apache Cell, un framework incluido en SOLR para la extracción de contenidos: Word, PDF, HTML, gracias a la librería Apache Tika.
En el siguiente post veremos un tutorial sobre cómo utilizar Apache SOLR a través de un ejemplo práctico, ya que tener estos conceptos claros será de gran ayuda. Hasta la próxima.
1 Comentario
¿Por qué no comentas tú también?
Muy buen resumen para comprender el funcionamiento de SolR.
Me gustaría saber si puedo haceros una consulta sobre un caso concreto.
Un saludo!
Ruben Hace 6 años
Hola Ruben
Claro, cualquier consulta puedes contactarnos a través de https://www.irontec.com/contacto
Un saludo
Victor Saldarriaga Hace 6 años
Queremos tu opinión :)