Muy buenos días a todos !
Esta vez: VoIP, pero VoIP con bastantes componentes de System’s y algo de networking básico 🙂
Hemos aprovechado este periodo de verano, que muchos clientes están de vacaciones 😉 para hacer este pequeño post que teníamos pendiente desde hace muchíiiisiiiimo tiempo: Cual sería el planteamiento recomendable para montar una infraestructura IP PBX escalable quasi de forma línea líneal en la que los recursos no se vean desaprovechados ?
Es decir, vamos a ir desarrollando de forma paulatina lo que sería una arquitectura que evite la muy conocida estrategia Activo-Pasivo, que si bien no está mal, por ser muy sólida/estable/probada, no crece de forma lineal:
- ¿Cómo hacemos si el servidor activo se empieza a quedar corto?
- ¿Tienen que ser los dos servidores iguales? ¿Qué pasa si pongo el que generalmente será esclavo algo peor?
La tendencia y lo que está «de moda» en los últimos años es tender hacia micro-servicios y containers fácilmente desplegables «en un formato conocido», superado ya el concepto de virtualización, ahí es donde Docker realmente está encontrando su hueco.
Si nos pudiéramos abstraer …
Con lo que si hablamos desde un punto de vista totalmente VoIP Agnostic, Asterisk Agnostic, una conversación tipo reducida al máximo sería:
- ¿Cuantos usuarios, 15 000? Ummm, asumiendo un comportamiento normal de IVR’s, Salas de Conferencias y tal, umm serán 15 000 / 1000 = 15 contenedores – EOF – FIN del análisis ;).
Y si tenemos el tema de orchestration ya resuelto (con algo tipo Shipyard):
- Tenemos capacidad de carga en nuestro barco, digo cloud, digo porta-contenedores, sin problemas: Green Light al proyecto.
Jejeje, ojalá todo fuera así no ? Como si la computación y los proyectos se pudieran asemejar a la generación de electricidad ((que no decimos que sean fáciles tampoco sus problemas, pero al menos no los conocemos jijiji)) más consumo, se está disparando, algo así como «Ingenieros VoIP atentos: a nuestros clientes les ha tocado la lotería y no paran de llamar, dale-dale mete mas containers, otros 8 mínimo, rápido!»
Bajando a la sala de máquinas
Obviamente, nada es así de fácil, los que trabajamos en estos mundos, bien sea en proyectos VoIP o en cualquier otro proyecto IT, hay muchísimas variables a tener en cuenta que pueden ser determinantes. Si nos centramos en Asterisk, las preguntas que rápidamente se nos disparan cuando pensamos en activo-activo:
- ¿Que pasa con los usuarios? Si un usuario A está registrado en el servidor X y le llama un usuario B que está en Y, como sabe X donde está ?
- ¿Que pasa con la pseudo-presencia (BLF) ? Si la llamada la está gestionando en servidor X, como sabe el servidor Y que ese usuario está ocupado y así poder informarle al usuario Alice de que Bob estña ocupado.
- Mis locuciones? Los usuarios se están venga a personalizar su buzón de voz, que pasa con las locuciones !
- Y el CDR ? Mi cliente requiere un CDR preciso-preciso, que hago ?
- Y las colas ? Que pasa con las colas? ¿Cómo se encajan en este nuevo mundo de activo-activo?
Bueno, la verdad es que es abrir una puerta y casi querer cerrarla y asumir que el motor funcionará sólo ! Son bastantes retos jiji 😉
Preparando la armada: Docker on the wave!
Bueno, visto lo visto con los retos que tenemos, vamos a dejar esos desafíos para mas adelante en nuestro post y nos centramos ahora en desplegar una infraestructura base que nos permita lanzar decenas «micro servicios» Asterisk al mar de forma ágil.
La verdad es que Docker tiene múltiples ventajas, sobre todo para los flujos Dev/Test/Prod y la relación entre SysAdmin’s y Dev Teams, y para el propósito que tenemos en este post nos encaja perfectamente a nivel conceptual: Desplegar de forma ligera procesos Asterisk de forma controlada, aislada y sin tener que lanzar VM’s «pesadas» con todo su Init/Systemd , Kernel completo y tal. La verdad es que da gusto estar en un container hacer un «ps aux» y ver sólo 1 o 2 procesos, de hecho, en algún que otro proyecto apostamos por estrategia de despliegue ágil con Xen y VM’s con storage volátil en Ramdisk para plantear la misma estrategia global de containers de Docker 😉 Lo que está claro es si todo acaba tendiendo hacia este tipo de soluciones, hay que ir adaptando la cabeza … tantos años por los mismos tipos de sendas 😉
Lo que si sucede con Docker, a fecha de hoy, es que el modelo de networking está creciendo y adaptándose de forma rápida, pero a día de hoy, el concepto de «Ship It! Run Everywhere» basado principalmente en contenedores que están tras NAT del anfitrión no encaja del todo, bastantes retos existen ya, aunque el NAT sea un problema resuelto como comentaba hace muuucho tiempo nuestro gran amigo Saghul, si lo evitamos por el momento, mejor que mejor 😉 Dicho esto y viendo el modelo de networking de Docker:
- Bridge (Docker gestiona un bridge, default docker0, container sale «nateado»).
- Host (Comparte stack con el anfitrión).
- None (Container dispone de stack pero Docker no configurará nada ni lo gestionará).
- Container (Compartido entre containers).
Viendo las opciones, en nuestro escenario de pruebas, usaremos Docker dentro de un cluster grande Proxmox’s con iSCSI, vlans y tal que tenemos para todas estas pruebas, el que mas nos encaja es bridge, pero un poco customizados, lo que tenemos sería mas o menos así:
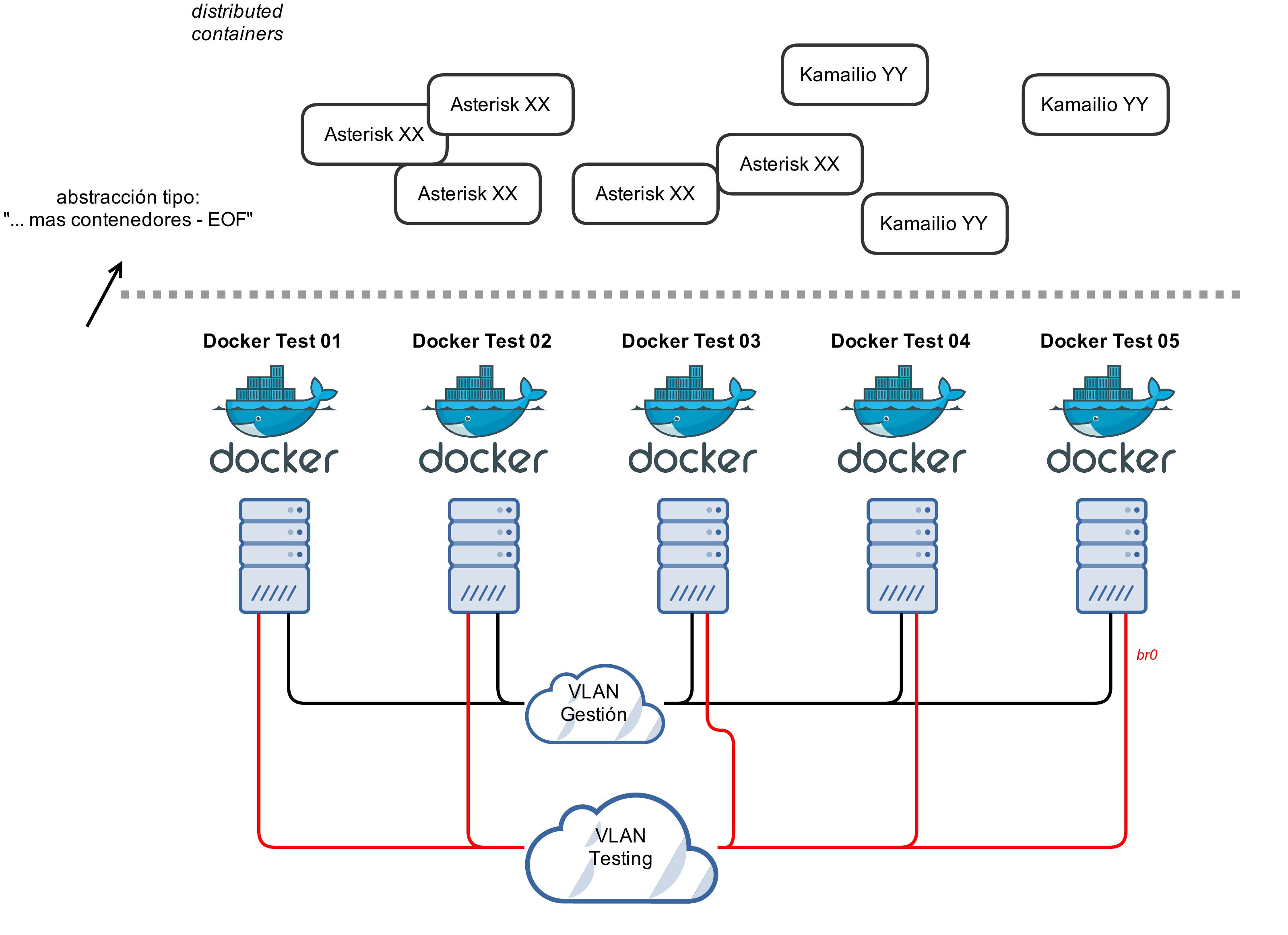
Es decir, a nivel de networking dejaremos que cada server Docker gestione con el modelo bridge standard la asignación de IP’s, así podemos ejecutar los containers de forma limpia sin parámetros LXC especiales o gestiones ajenas a Docker. El único punto importante a tener en cuenta es que al compartir espacio de direccionamiento, hay que gestionar el bloque de IP’s que cada server asigne, para evitar conflictos.
Dicho esto, una vez tenemos Docker instalado, en nuestro caso, todas las configuraciones las comentaremos para Debian Wheezy 7.x la configuración tipo a tener en cuenta:
Tener un bridge propio creado con una interface hacia la VLAN compartida
Se puede hacer tb con Open vSwitch, con bridge-utils clásicas, a modo de ejemplo /etc/network/interfaces:
auto br0
iface br0 inet static
address 10.10.10.130
netmask 255.255.255.224
network 10.10.10.128
bridge_stp off
bridge_fd 0
bridge_ports eth1
y en /etc/default/docker:
DOCKER_OPTS="-H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock -b br0
De esta forma, si ejecutamos mismamente:
docker run -it debian bash
Estaremos en un container con la primera IP del rango 10.10.10.128/27 entregada.
En este caso, la opción de escuchar en TCP2375 la hemos activado para luego poder realizar la orquestación de la flota 😉
Especificar a cada Docker Daemon su rango
La opción que nos viene muy bien para este caso de bridge distribuido:
--fixed-cidr=""
IPv4 subnet for fixed IPs (e.g., 10.20.0.0/16); this subnet must be nested in the bridge subnet (which is defined by -b or --bip)
Así pues, en nuestro ejemplo estamos usando la red 10.10.10.128/27, y hemos comentado que tenemos 5 servidores, así que: /27 = 2 /28 = 4 / 29, con lo que para que cuadre mejor lo dejaremos en 4 /29 y por tanto 4 servidores, que dividiremos tal que:
- docker01: 10.10.10.128/29
- docker02: 10.10.10.136/29
- docker03: 10.10.10.144/29
- docker04: 10.10.10.152/29
A modo de ejemplo, en el servidor docker01, su /etc/default/docker quedaría tal que:
DOCKER_OPTS="-H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock -b br0 --fixed-cidr=10.10.10.128/29"
Almirantazgo
Hasta ahora tenemos nuestros 5 buques porta-contenedores, pero si a lo que estamos jugando es a abstraerse, se debería poder tratar como uno solo y que el scheduling, restarting, ha y tal se gestione.
El caso es que sólo esta parte puede dar para escribir numerosos posts desde el área de sistemas 😉 Lo mas interesante que hemos visto es FLEET para CoreOS, un INIT distribuido global.
De forma nativa, la gente de Docker le está dando bastante empuje a SWARM, en nuestro caso, hemos optado por Shipyard para poder poner pantallazos web bonitos por aquí 😉 Como comentábamos, no se trata de un post sobre Docker, ya nos estamos extendiendo bastante ya …
La verdad es que se instala de forma muy sencilla, gracias que, como era de esperar, es un container:
docker run --rm -v /var/run/docker.sock:/var/run/docker.sock shipyard/deploy start
Una vez que lo hemos cargado, tendremos los 3 containers que lanza ready’s:
root@zgor-docker-01:~# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7b9f21dc3824 shipyard/shipyard:latest "/controller" 2 days ago Up 3 hours 0.0.0.0:8080->8080/tcp shipyard d8c45e06bf58 shipyard/rethinkdb "/usr/bin/rethinkdb 2 days ago Up 3 hours 0.0.0.0:32770->8080/tcp, 0.0.0.0:32769->28015/tcp, 0.0.0.0:32768->29015/tcp shipyard-rethinkdb 9ad116a3d822 shipyard/rethinkdb "/bin/bash -l" 2 days ago Up 3 hours 8080/tcp, 28015/tcp, 29015/tcp shipyard-rethinkdb-data
y si accedemos al 8080TCP veremos que sale ya el login de Shipyard (default admin / shipyard).
El dar de alta los Engines (Docker Daemons) es bastante trivial (hay que acordarse de tener las DOCKER_OPTIONS que permitan al demonio escuchar en TCP y no sólo en UNIX Socket), y nos quedaría algo así como:

Validando nuestra flota

Antes de continuar, conviene arrancar debian’s, digo lanzar varios containers y confirman que se ven entre sí:
root@zgor-docker-01:~# docker run -it zetagor/debian8 bash root@zgor-docker-02:~# docker run -it zetagor/debian8 bash root@zgor-docker-03:~# docker run -it zetagor/debian8 bash root@zgor-docker-04:~# docker run -it zetagor/debian8 bash
y, efectivamente, vemos que se pingan entre sí:
root@dc60e4fd3f97:/# ping 10.10.10.146 PING 10.10.10.146 (10.10.10.146) 56(84) bytes of data. 64 bytes from 10.10.10.146: icmp_seq=1 ttl=64 time=1.04 ms ^C
Primera batalla: BLF’s distribuidos
El concepto de presencia básica con BLF’s, en nuestra opinión la más usada en PBX Corporativas con hardphones sencillos, dadas las limitaciones de los terminales a soportar presencia completa tipo SIP SIMPLE con el modelo PUBLISH/SUBSCRIBE/NOTIFY y XCAP para las listas / políticas de acceso, es uno de los principales retos, dado que en un Asterisk mono-server tradicional es sencillo: se vincula un hint a un SIP Device State y fin:
exten = 6002,hint,SIP/Bob
Asterisk ya se encarga de todo 🙂
Pero si empezamos a pensar en distribuido/múltiples servidores, la cosa cambia. ¿Como hacemos para que un servidor se entere de un cambio de estado que sucede en otro? Si analizamos las diferentes posibilidades, desde nuestras queridas versiones 1.8.X, las estrategias que podríamos seguir:
- Distibuted Device State con OpenAIS (desde 1.8)
- Distributed Device State con XMPP (desde 1.8)
- Distributed Device State con PJSIP de forma pseudo nativa (no disponible en 1.8)
En épocas previas, hemos hecho bastantes pruebas con OpenAIS y la verdad es que se comporta «mas o menos» bien, no es tolerante a restart’s de corosync ni gestiona temas de «votaciones» ni «pulling» al inicio (con lo que hay que scriptear en boot-time de Asterisk), pero la verdad es que hacerlo por SIP, y sobre todo con la solidez demostrada por PJSIP, nos parece el camino más interesante y sobre todo, el que mas recorrido plantea.
Lo interesante/potente de que sea vía SIP Standard, es que todo el potencial que nos aporta Kamailio, lo podemos aplicar, es un SIP Publish «standard» (tienen un body específico), pero al ser SIP, lo podemos rutar, branching, capturar fácilmente y debugging, en definitiva, gestionarlo como queramos.
En lo que respecta la parte de Asterisk, es importante que tengamos en cuenta que es vía chan_pjsip, hay que olvidarse de chan_sip.c, la config la explican muy bien desde Digium:
El punto importante es que, al necesitar realtime (donde guardaremos los SIP Endpoints accesibles para todos los containers), hay que pelearse un poco con Sorcery para que permita ambas configuraciones (Realtime y fichero, ya que parece que hay algún bug todavía con con la config de la publicación en realtime), quedando el fichero sorcery.conf algo así como:
[res_pjsip] endpoint=realtime,ps_endpoints endpoint=config,pjsip.conf,criteria=type=endpoint auth=realtime,ps_auths aor=realtime,ps_aors domain_alias=realtime,ps_domain_aliases contact=realtime,ps_contacts voicemail=realtime,voicemail [res_pjsip_endpoint_identifier_ip] identify=realtime,ps_identify [res_pjsip_outbound_publish] outbound-publish=config,pjsip.conf,criteria=type=outbound-publish [res_pjsip_pubsub] inbound-publication=config,pjsip.conf,criteria=type=inbound-publication [res_pjsip_publish_asterisk] asterisk-publication=config.pjsip.conf,criteria=type=asterisk-publication
(asumiendo que queremos voicemail y tal tb en RT, acordarse luego de extconfig y odbc si procede)
La parte de PJSIP, quedaría configurada en pjsip.conf tal que:
[ast2] type=endpoint [ast2-devicestate] type=outbound-publish server_uri=sip:[email protected] event=asterisk-devicestate [ast2] type=inbound-publication event_asterisk-devicestate=ast2 [ast2] type=asterisk-publication devicestate_publish=ast-devicestate device_state=yes
Y con eso, ya tenemos a nuestro querido Asterisk enviando Publish a 10.10.10.190 cada vez que cambia algún device state, y no estamos obligados a usar CustomDevice’s ni nada. A modo de ejemplo, nuestro querido SNGREP nos lo muestra tal que:

Como podéis ver, es una request sip standard, con el device state serializao en JSON, vamos, que fácilmente debuggable capturando y tal.
Así que si llegados a este punto, un Hello World es lo que realmente mas apetece 😉 Así que manos a la obra:
Con nuestro querido Docker, lanzamos un par de contenedores Asterisk:
root@zgor-docker-01:~# docker run -d zetagor/blogpost_astpjsip runasterisk root@zgor-docker-01:~# docker run -d zetagor/blogpost_astpjsip runasterisk
y verificamos lo fácil que ha sido lanzar dos Asterisk one-liner style 😉 :
root@zgor-docker-01:~# docker ps | grep asterisk 1e39f99283bc zetagor/blogpost_astpjsip "runasterisk" 2 minutes ago Up 2 minutes e8c70afecd2d zetagor/blogpost_astpjsip "runasterisk" 2 minutes ago Up 2 minutes
Podemos comprobar que IP’s han cogido estos containers con docker inspect XXX o directamente un attach y luego «!ifconfig» desde el CLI Asterisk.
Así que por el momento vamos hardcodear la lógica en nuestro Kamailio gestor/router de BLF’s, con la config por default que viene con los paquetes Debian que tan amablemente ponen a nuestra disposición, tocamos únicamente la parte de PUBLISH:
route[PRESENCE] {
if(!is_method("PUBLISH|SUBSCRIBE"))
return;
if (!t_newtran()) {
sl_reply_error();
exit;
}
if(is_method("PUBLISH"))
{
$du="sip:10.10.10.137";
t_relay();
}
exit;
}
Como podéis ver, se trata de una prueba rápida cambiando la destination uri, nada más, para ver si lo encamina bien y sobre todo ver si el Asterisk contrario (10.10.10.137 lo gestiona bien al recibir).
Haciendo una llamada desde el PJSIP Endpoint «wifizgorcasa», vemos que efectivamente, Kamailio recibe el PUBLISH y lo ruta perfectamente:
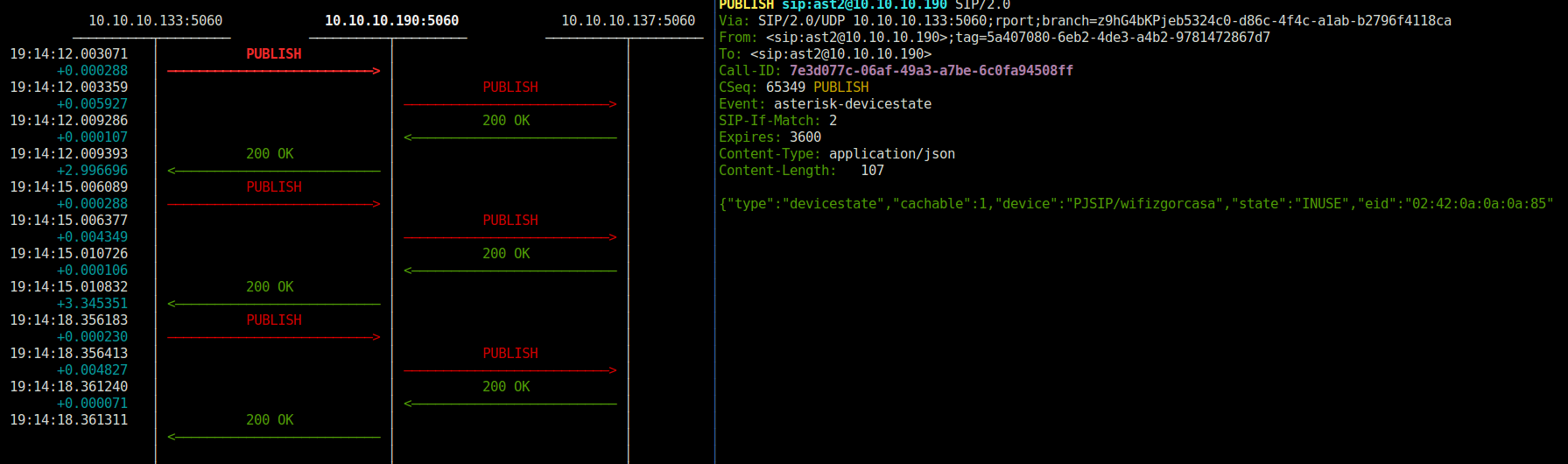
Endpoint: wifizgorcasa In use 0 of inf
y luego, tras recibir el cambio de estado:
Endpoint: wifizgorcasa Not in use 0 of inf
Awesome! La prueba de concepto funciona casi out of the box como podéis ver 😉 (Asterisk 13.2, Kamailio cualquier versión).
Segunda batalla: Repartiendo los eventos PUBLISH de forma eficiente
La prueba de concepto, es eso, algo para probar rápido y mantener la sangre caliente en estos lares 😉 Pero si queremos plantearnos hacer algo medianamente serio con esto, el Kamailio que recibe y reenvía los eventos tiene que saber a quien se los tiene que mandar y sobre-todo, distribuirlos de forma paralela, un caso claro de Paralel Forking necesario mas allá del clásico Invite multi-contact
Nos planteamos algo como esto a nivel conceptual:
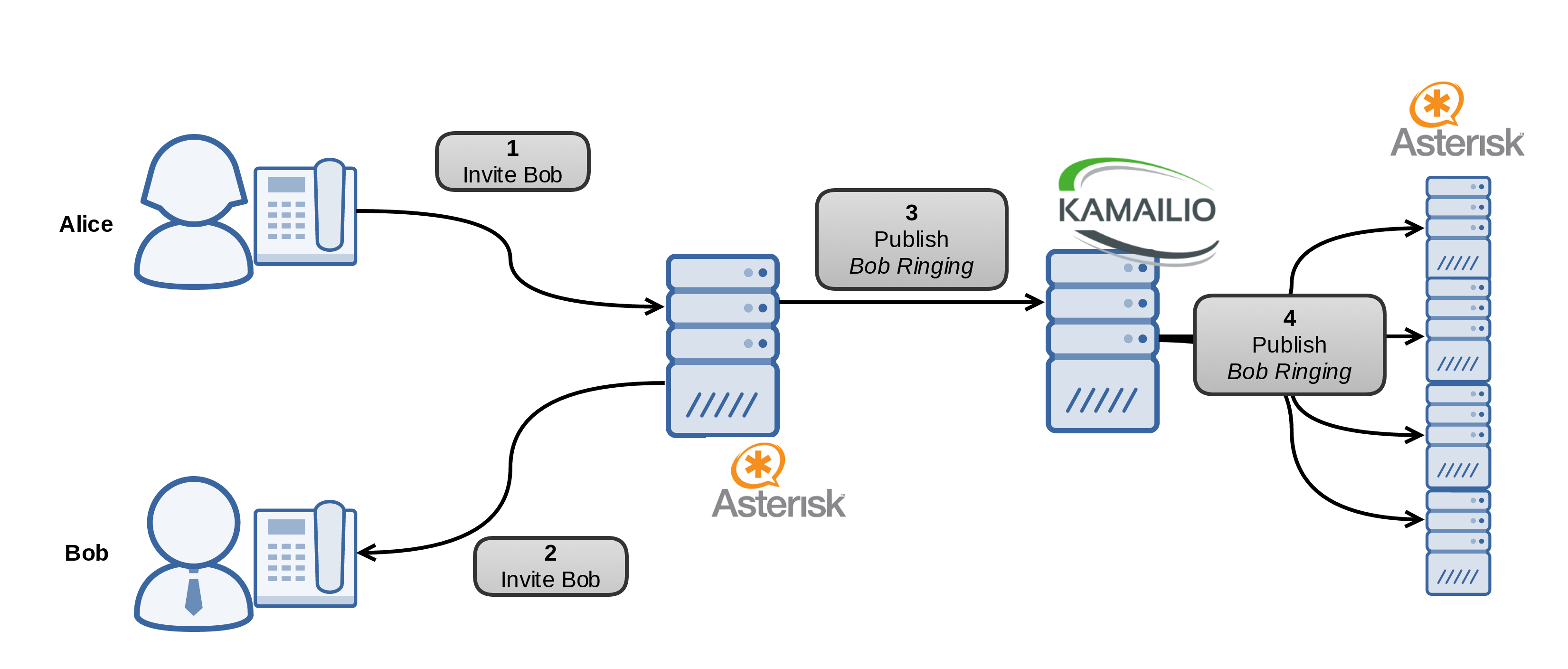
En este pseudo-esquema, hemos obviado que el primer servidor Asterisk enviará un Publish por Alice (IN USE) y varios por Bob (Ringing, In Use).
Así que se nos plantean varios retos técnicos muy interesantes:
- ¿Como sabe Kamailio que servidores Asterisk están vivos?
- ¿Como hace Kamailio para enviar en paralelo dicho Publish?
Para el primer reto, existen varios módulos que cumplen dicha función, con el que mejor y más experiencia tenemos es con DISPATCHER Module, pudiendo ser configurado en BBDD o mismamente en un fichero con una syntaxis específica, que será lo opción que cojamos para estas pruebas, así pues, nos construimos un fichero de este estilo, dando de alta todos los posibles containers, estén arrancados o no (esto se podría mas del estilo de Discovery Services, y hacer que sea tabla dinámica, pero no es el objetivo actual):
root@zgor-docker-kamailio:/var/run/kamailio# cat /var/run/kamailio/dispatcher.list # $Id$ # dispatcher destination sets # # line format # setit(int) destination(sip uri) flags(int,opt) priority(int,opt) attributes(str,opt) 1 sip:10.10.10.129:5060 0 0 1 sip:10.10.10.130:5060 0 0 1 sip:10.10.10.131:5060 0 0 1 sip:10.10.10.132:5060 0 0 1 sip:10.10.10.133:5060 0 0 1 sip:10.10.10.134:5060 0 0 1 sip:10.10.10.135:5060 0 0 1 sip:10.10.10.136:5060 0 0 [ ...... ]
Una vez tenemos el fichero creado, la configuración en Kamailio en lo que respecta los módulos (cargar dispatcher y sctp – importante – sino, no lanzará SIP OPTIONS periódicos):
loadmodule "dispatcher.so"
loadmodule "sctp.so"
# ----------------- setting module-specific parameters ---------------
# dispatcher module
modparam("dispatcher", "list_file", "/var/run/kamailio/dispatcher.list")
modparam("dispatcher", "ds_ping_interval", 15)
modparam("dispatcher", "ds_ping_from", "sip:[email protected]")
modparam("dispatcher", "ds_probing_mode", 1)
#modparam("dispatcher", "ds_ping_reply_codes", "class=2;class=3;class=4;class=5")
De esta config, comentar únicamente que se enviará SIP OPTIONS cada 15 segundos, que se enviarán a todos (ds_probing_mode) y que cualquier respuesta será considerada como que está vivo – que es lo que nos interesa, al no tener que probar salidas a PSTN y tal, con saber únicamente «que hay vida» nos vale, y la respuesta de Asterisk difiere entre versiones (en Ast13 con PJSIP se obtiene un bonito 401 Unauth)
Para poder ver que está funcionando bien el probing, lo mas fácil es lanzar un sngrep y ver los SIP OPTIONS continuos, y para validar que in-memory Kamailio lo tiene todo correcto, el comando sería: kamctl fifo ds_list, a modo de ejemplo:
root@zgor-docker-kamailio:/# kamctl fifo ds_list SET_NO:: 1 SET:: 1 URI:: sip:10.10.10.137:5060 flags=IP priority=0 attrs= URI:: sip:10.10.10.136:5060 flags=IP priority=0 attrs= URI:: sip:10.10.10.135:5060 flags=IP priority=0 attrs= URI:: sip:10.10.10.134:5060 flags=AP priority=0 attrs= URI:: sip:10.10.10.133:5060 flags=AP priority=0 attrs= URI:: sip:10.10.10.132:5060 flags=IP priority=0 attrs= URI:: sip:10.10.10.131:5060 flags=IP priority=0 attrs=
Como podemos ver, tenemos dos servidores Asterisk que están vivos (con el flag A de Active) y que están siendo todos testeados.
La llamada a utilizar con el módulo dispatch será: ds_select_domain(«1″,»4»); , irá seleccionando el siguiente salto en forma de round «robin», es decir, tras llamarlo nos seteará $du correctamente. Utilizamos ds_select_domain en lugar de ds_select_dst para que cambie igualmente el domain de la request-uri, que aunque a Asterisk realmente le suele dar igual eso, siempre conviene 🙂
Por el momento, no estamos resolviendo el tema del branching, solo queremos hacer que Kamailio gestione una lista de los Asterisk vivos y que tienen que ser notificado, así que lo construiremos primero con balanceo simple para probar:
if(is_method("PUBLISH"))
{
ds_select_domain("1", "4");
$avp(s:temporal) = "sip:" + $si + ":5060";
if ($avp(s:temporal) == $du)
{
# Se ha seleccionado el mismo gw que el origen, hay que pedir otro
ds_select_dst("1","4");
$avp(s:temporal) = "sip:" + $si + ":5060";
if ($avp(s:temporal) == $du)
{
# No hay ningun otro Asterisk vivo, respondemos y FIN
sl_send_reply("200", "OK");
exit;
}
}
t_relay();
}
La comparación es únicamente para no devolver al mismo servidor origen 😉 (se podría matchear de otra forma mas limpia, es ilustrativo todo esto)
Para probar el balanceo, de nuevo con SNGREP se ve muy fácilmente (Asterisk mantiene diálogo en los sucesivos PUBLISH):
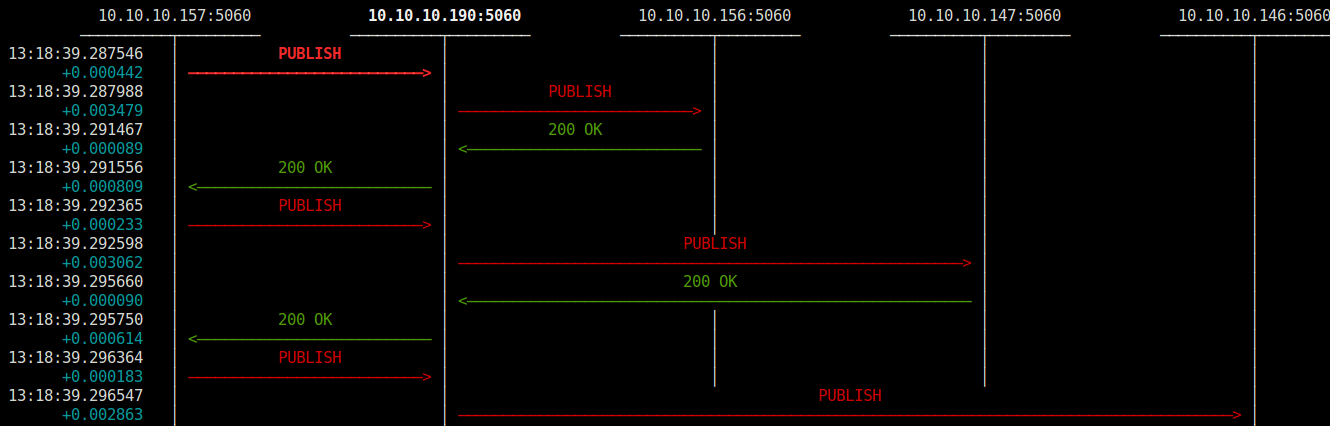
Muy bien … llegados a este punto ya tenemos un Kamailio que es capaz de republicar esos estados de forma concisa, pero siempre 1 a 1, no 1 a N 🙂
Y ahí es dónde entra en juego el potencial de distribuir vía SIP los Device State’s en Asterisk, tenemos toda la magia (blanca y mas oscura jiji) que Kamailio nos puede dar, así que basta una llamada a append_branch para forkear de forma limpia 🙂 De nuevo nuestra power tool SNGREP nos lo muestra de forma limpia como queda:

A modo de ejemplo, en este caso, el Kamailio 10.10.10.190 etá recibiendo una publicación de un cambio de device state enviado por el container 10.10.10.156, a modo de pruebas, estamos sacando branches para otros dos containers, que reciben dicho mensaje, lo procesan y actualizan su tabla de states.
Es decir, con una única llamada a append_branch por cada posible destino, ya encarga Kamailio de gestionarlo.
Para dejarlo bien, habría que acceder a la estructura de gateways, ir recorriéndola y append_branch, validando no re-publicar al emisor, gestionar los branch, failure’s routes y tal si procede 😉 No queremos tampoco entrar en excesivos detalles :D)
La batalla del flujo de entrada
Muy bien, ya tenemos nuestras Asterisk boxes auto-distribuyéndose ellas mismas los device’s states, ahora nos queda balancear la entrada, por lo que queremos, de forma absoluta:
- Cualquier diálogo iniciado por un SIP UA debe poderse enviar a cualquier servidor Asterisk que este vivo, bajo cualquier circunstancia.
En su momento ya comentamos las ventajas de utilizar el módulo path, permitiendo que todo funcione sin tocar las R-URI y siendo todo mas limpio, así que nos pasaremos en esa misma config.
En nuestro ejemplo, el objetivo importante del post está siendo evaluar el el crecimiento horizontal de Asterisk principalmente, pero en futuros posts ya tomamos nota para comentar temas de registros SRV, NAPTR y derivados, para permitir la distirbución automática en entrada por parte de los SIP UA’s.
Así que llegados a este punto utilizaremos el mismo Kamailio para repartir juego, haciendo uso como está mandado del mismo módulo DISPATCHER, pero para las request’s de tipo REGISTER:
route[REGISTRAR] {
if (!is_method("REGISTER")) return;
if (!ds_select_domain("1", "4"))
{
sl_reply("503","No Asterisk Available ");
exit;
}
add_path();
append_hf("Supported: path\r\n");
t_relay();
exit;
}
Sin mucho truco, estamos ya enviando el REGISTER de forma balanceada a cada servidor.
Y sí, podríamos gestionarlo por fuera, pero ahora que Asterisk está con PJSIP y soporta multi-contact: ¿Por qué no utilizarlo y que Asterisk los tenga controlados para poder tomar decisiones en el dialplan?
¿Pero que pasa si el servidor que tiene el Register en ese momento muere? ¿Cómo saben los otros servidores como llamarle?
Al utilizar RT, tanto el contacto como el Path están guardados en la BBDD, podemos acceder de forma RAW a cualquiera de nuestros containers y lanzar algo tipo esto:
asterisk -rx "channel originate PJSIP/XXXX application Echo"
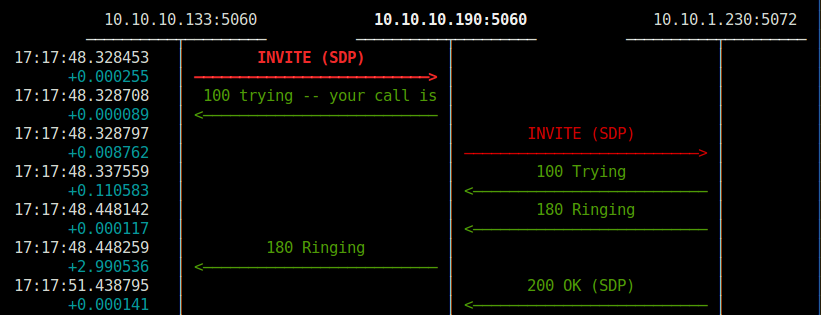
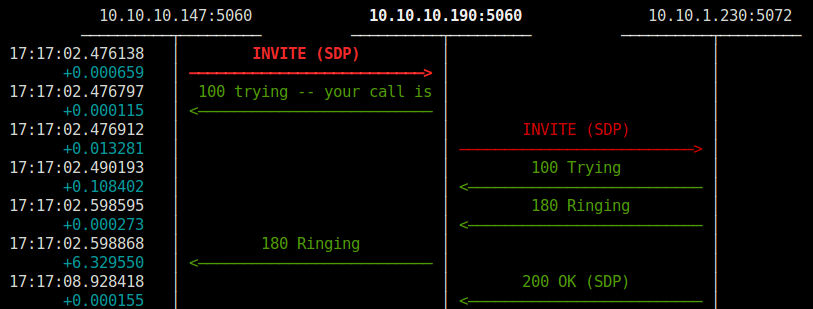
Si lo probamos desde dos diferentes totalmente al azar (10.10.1.230 es un hadphone, 10.10.10.190 es el Kamailio de pruebas de este post)
Container Random (133)
Container Random (147)
La película para ver con palomitas
Tal y como sentenciaba nuestro gran Kaian : «El telemarathon lo veremos con palomitas», vamos a recogerle el testigo y crearnos toda esta película que nos hemos montado en algo digno de ver tranquilamente y que no parezca la consola de unos frikones 😉 con tanto tail -f, tcpdump, sngrep, clis y demás.
Así que nos hemos propuesto lo siguiente:
- Capturar tráfico SIP en el Kam principal
- Iniciar una prueba de carga con SIPP mismamente, sin XML escenarios, los built-in bastarán.
- Jugar a hundir la flota con nuestros containers
- Pasarlo por el bestial Etherape para construir un vídeo digno 😉
El dialplan compartido por los containers, como véis en el flujo anterior, no tiene nada, un 180 Ringing temporary y al de 2 segundos un 486 Busy como respuesta final.
El vídeo nos queda tal que:
El storyboard pre-producción
Como en todo guión de película, el nuestro no se iba a quedar corto 😉 jiji, aquí os lo presentamos:
Secuencia 01: Comercial jefe respondiendo a un cliente que quiere escalar x50 de la noche a la mañana

Secuencia 02: Los técnicos no se acuerdan del botón mágico

Secuencia 03: Zoom en el magic button
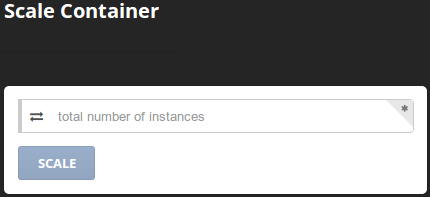
A fin de cuentas, para algo hemos montado todo esto no ? ¿No queríamos tener un botón mágico que permita estirar la capacidad como quien se tira de puenting con toda la fé del mundo?
Pues aquí está, gracias a nuestro querido Shipyard:

y crezcamos como queramos:
Tras el telón …
Este post, como habéis podido leer si habéis tenido la suficiente paciencia, se ha limitado a exponer de forma muy superficial los retos principales en la búsqueda del escalado horizontal que todo proyecto grande hoy por hoy se merece, hay muchos conceptos fuera de scope (BBDD? Si / No / Cómo , shared storage, que pasa con las Queues? ) y otros que nos hubiera gustado profundizar mas (orquestación, proceso de arranque inicial y posibles early testing prototypes como ir guardando en Kamailio igualmente y re-publicar tras un Register inicial de cada nodo para indicar su boot time y soluciones similares).
Mismamente, en las configs de Kamailio habría que ser mucho mas granular, gestionar las failure routes para descartar el gateway en caso de fallo automáticamente y tal, sin tener que esperar a que pase el check periódico …
Pero el tiempo, como todos sabéis es finito y otros deberes nos llaman 🙂
La parte de Docker, para auto-escalado on-demand, a nivel productivo no lo vemos todavía, hasta que alguno de los hosters principales se decante por ofertar soluciones Container on-demand – al igual que haríamos con proyectos grandes en Amazon EC2/AWS y su conocido auto-scale 😉
Nos vemos pronto por aquí !
1 Comentario
¿Por qué no comentas tú también?
Gorka, fantástico post…
Algunas dudas:
– Estoy empezando a leer cosillas sobre Docker y cuentan que aun está muy fresco para producción. ¿Lo has metido en producción?
– Sobre la instalación de Docker no cuentas nada, ¿lo instalas en la propia máquina PROXMOX o sobre algún contenedor creado en éste?
Gracias y saludos
Juan García Hace 9 años
Aupa Juan,
En producción por el momento, por aquí nada de nada … para pruebas y tal por el momento.
El tema es que lo de Proxmox es porque tenemos un cluster con bastantes nodos y storage y tal, con lo que para pruebas, nos encaja muy bien, así que realmente lo que hicimos es Docker sobre VM’s (KVM) de Proxmox. Lo que no creo que funcione es containers Docker sobre container Proxmox, aunque ahora que Proxmox 4 es LXC, igual con privileged containers y tal sí.
La instalación, tal cual, del script de get.docker.com (o algo parecido), sin problema alguno en Debian 8.
Gracias a ti!
Gorka Gorrotxategi Hace 9 años
Ah, bien, entonces a ver si lo he entendido:
PROXMOX1 <—| | <— Cont1 (Ast1)
| <— Storage <— VM (KVM con Debian 8) <— Docker (get.docker.com ) <—| <— Cont2 (Ast2)
PROXMOX2 <—| | <— Cont3 (Ast3)
| | <— Cont4 (Kml1)
| | <— Cont4 (Kml2)
¿Esa es la arquitectura sobre la que estás hablando?
Saludos y gracias
Ramses Hace 9 años
Creo que con esto de que te elimina los espacios, se ha «escogorciado» un poco el esquema. A ver si sustituyendo los espacios por «puntos» se ve algo mejor…
Ah, bien, entonces a ver si lo he entendido:
PROXMOX1 <—|…………………………………………………………………………………………………………..| <— Cont1 (Ast1)
……………………..|…………………………………………………………………………………………………………..| <— Cont2 (Ast2)
……………………..| <— Storage <— VM (KVM con Debian 8) <— Docker (get.docker.com ) <—| <— Cont3 (Ast3)
……………………..|…………………………………………………………………………………………………………..| <— Cont4 (Kml1)
PROXMOX2 <—|…………………………………………………………………………………………………………..| <— Cont5 (Kml2)
¿Esa es la arquitectura sobre la que estás hablando?
Saludos y gracias
Ramses Hace 9 años
Aupa Ramses,
Si, algo así como lo que indicas.
De todas formas, hemos acabando probando así porque era mas fácil sobre lo que teníamos, y sobre todo para probar el tema de networking en multi-docker engine. Si eso no te interesa tanto, puedes ejecutar todo en el mismo Docker host y listo, al ser containers, te aguanta supuestamente muchas muchas instancias 🙂
Gorka Gorrotxategi Hace 9 años
Ah, bien, entonces tenéis un par de PROXMOX en cluster, que atacan a una unidad de almacenamiento, en esa unidad de almacenamiento tenéis creadas varias VM’s (KVM) con Docker Engine en cada una y repartidas entre las varias Docker Engines tenéis creados los containers docker de Asterisk y Kamailio.
Ahora sí he pillado el esquema completo, ¿no?.
Saludos
Ramses Hace 9 años
Aupa Ramses,
Si, exactamente eso 🙂 Lo único tb a tener en cuenta en la parte de networking es que las VM’s con que ejecutan Docker Engine tienen que tener una VLAN / Red compartida entre si, para facilitar toda la parte la de red. Por defecto Docker «natea» lo que salga de docker0 hacia la red normal y te mapea puertos y tal, así que para este escenario, lo mas sencillo es que estén todos los containers en la misma red así te ahorras NAT/Routing y tal. El bridge que usa docker se configura /etc/default/docker, dicho bridge, debería tener uno de los puertos attacheados una NIC que vaya a una VLAN/Red común entre los diversos Docker Engines.
Gorka Gorrotxategi Hace 9 años
Hola interesante , que especificaciones están usando en el cluster?
Ricky Hace 9 años
Hola a todos en Irontec.
Saludos desde Caracas Venezuela.
Fenomenal este articulo y los felicito.
Soy un poco novato en estos temas pero me apasiona linux, recientemente empecé a estudiar Docker y Asterisk.
Amigos hay temas que leyendo este articulo veo que desconozco totalmente y desearia si es posible me iluminaras con las areas (topicos y si es posible enlaces) que debo profundizar para comprender totalmente este articulo y un dia ponerlo en práctica.
Gracias por compartir su conocimiento. 🙂
Pedro Perez Hace 8 años
Queremos tu opinión :)