Muy buenas a tod@s!
Hacía ya cierto tiempo que no escribíamos por estos lares, en lo que a materia VoIP/Networking relacionado se refiere, pero no hemos querido desaprovechar la oportunidad, dado que la ocasión se lo merece!
Antes de entrar en harina, destacar que en el blog del proyecto OpenSIPS lo tienen muy muy detallado desde el plano técnico y recomendamos su lectura, de hecho, este post parte de dicha lectura:
Y, por otra parte, sin duda las diapositivas de RĂZVAN CRAINEA disponibles en google docs en este enlace.

Lo que es en este post, intentaremos ponerlo en práctica, contextualizado y detallando los aspectos básicos para poder tener un entorno de pruebas fácilmente.
Antes de nada: ¿Anycast?
Si buscamos referencias en los sites habituales de Internet, se dispone de muchas casuísticas diferentes expuestas, siendo principalmente el factor diferenciador vs unicast: La dirección IP, pongamos B, con la que se comunica la IP origen A no tiene que porque estar siempre atada al mismo nodo.
Es decir, en unicast el tráfico va siempre entre dos IP’s, de forma dirigida, con routing directo si están en el mismo dominio l2 o con routing indirecto (enrutado tradicional) si no lo están. En el caso de broadcast, se trata de tráfico hacia todo el dominio L2, como podría ser un ARP Request For o el que seguramente nos viene a tod@s a la mente: el clásico paquete broadcast de NetBIOS. Seguramente al hablar de anycast nos vengan a la mente protocolos «sencillos» como DNS de tipo pregunta/respuesta. Es decir, todo lo contrario a lo que es SIP, dónde hay diálogos-transacciones-record routing-contact headers- … dónde todo lo que tenga que ver con transacciones y diálogos es siempre importante.
De hecho, relacionado con anycast, es muy interesesante esta presentación de Shawn Zandi de Linkedin.
De hecho, nos permitimos coger una de sus diapositivas para ilustrar mejor el concepto y continuar con nuestro rumbo en este post:

Pues eso, lo dicho: La misma IP está en diferentes nodos / máquinas / entornos.
Montando el entorno anycast: QUAGGA FTW! (100 trying …)
El diseño que nos marcamos como objetivo, sin dibujar todavía los componentes SIP sería este:

Es decir, la idea es que 10.204.204.10 se comunique con 10.205.205.1, y que dicha IP destino no esté «atada» a ningún componente(server,router,container,orquestador,X).
Para ello, el camino que cogemos es OSPF, existen otras vías, pero esta nos convence, dado podemos ir levantando nodos sin tener que preocuparnos de sesiones BGP, para lo que queremos encaja muy bien.
- La IP 10.206.206.1 es una IP de Loopback o Dummy en los 3 servidores.
De base, para tener la IP everywhere algo tal que:
servidorA# ip a add 10.206.206.1/32 dev lo servidorB# ip a add 10.206.206.1/32 dev lo servidorC# ip a add 10.206.206.1/32 dev lo
En lo que respecta el protocolo de routing dinámico que nos permitirá hacer todo esto, hablamos de OSPF y de equal cost multipath, es decir, «mismo coste» por varios caminos diferentes.
En lo que respecta las configuraciones de routing, las siguientes se presentan ejecutadas en Quagga, pero cabe destacar que lo mismo funcionaría en otros vendors (Cisco, Juniper, Ubiquiti EdgeOS(Vyatta))
router
ospfd: router ospf ospf router-id 10.205.205.254 redistribute connected network 10.205.205.0/24 area 0.0.0.0
En router poco más que añadir, acordarse de activar el ip_forwarding!
server1
router ospf ospf router-id 10.205.205.11 network 10.205.205.0/24 area 0.0.0.0 network 10.206.206.1/32 area 0.0.0.0
server2
router ospf ospf router-id 10.205.205.12 network 10.205.205.0/24 area 0.0.0.0 network 10.206.206.1/32 area 0.0.0.0
server3
router ospf ospf router-id 10.205.205.13 network 10.205.205.0/24 area 0.0.0.0 network 10.206.206.1/32 area 0.0.0.0
Es decir, y resumiendo de nuevo:
- Los 3 servidores tienen la IP 10.206.206.1/32
- Los 3 servidores la anuncian por OSPF.
¿Y esto funciona?
Para comprobarlo, basta con ejecutar el comando ip route show en el equipo router y ver los diferentes next-hop’s:
10.206.206.1 proto zebra metric 20 nexthop via 10.205.205.11 dev ens9 weight 1 nexthop via 10.205.205.12 dev ens9 weight 1 nexthop via 10.205.205.13 dev ens9 weight 1
PCAP or it didn’t happen!
Pues sí, buena petición sí 😉
Capturando tráfico vemos que, efectivamente, tenemos multipath-routing pero:
- Per-flow multipath
Es decir, entre un SIP UAC 5060UDP contra 10.206.206.1 5060 UDP, el path será siempre siempre el mismo. Con el tema del multipath routing, principalmente lo que se busca es lo contrario a lo que estamos buscando nosotros.
Lo que hemos visto como más significativo para ilustrar los cambios en multipath routing es esta frase:
Es de Peter Nørlund, enviada en la la lista de NET DEV del Kernel:
When the routing cache was removed in 3.6, the IPv4 multipath algorithm changed
from more or less being destination-based into being quasi-random per-packet
scheduling. This increases the risk of out-of-order packets and makes it
impossible to use multipath together with anycast services.
Sobre este punto, si estáis interesad@s en todo esto, estos links nos han parecido clave en nuestro research:
- Información general de estos conceptos en EmbeddedLinux
- El blog en sí de Vincent Bernat, el MTU Ninja ! (alucinante!)
- El kernel patch dónde se comenta el cambio para traer de vuelta anycast
- Un hilo muy interesante en Unix Stackexchange relativo al multipath routing con kernel’s 4.4
Montando el entorno anycast: QUAGGA FTW! (302 Redirect Contact: QUAGGA + GNS3)
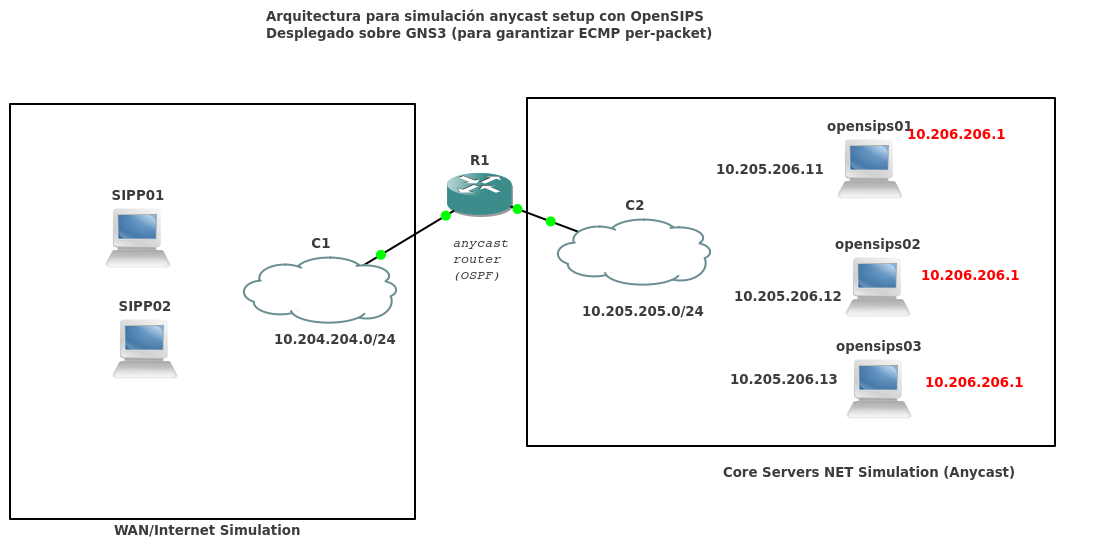
Finalmente, para no liarnos demasiado, que al final estamos hablando más de linux networking que de SIP / OpenSIPS, optamos por montar un entorno hibrido, ilustrado con el esquema a continuación, que se resume en:
- Cambiamos el router principal quagga por un Cisco simulado con GNS3
- Cisco si que hace facilmente per-packet true multipath routing
Y cómo GNS3 nos permite conectarlo contra instancias o bridges locales, podemos unirlo contra los OpenSIPS, y con la ventaja de usar protocolos standard como OSPF, automáticamente tenemos
Si finalmente optáis por ir probando este camino, la configuración del Cisco Router en GNS3 tendría que tener la configuración para el per-packet load balancing:
interface FastEthernet0/0 description "Hacia 10.204.204.0/24" ip address 10.204.204.254 255.255.255.0 ip load-sharing per-packet duplex auto speed auto ! interface FastEthernet0/1 ip address 10.205.205.254 255.255.255.0 ip load-sharing per-packet duplex auto speed auto !
PCAP Reality 😉
Capturamos directamente en la salida del router (dado que el cliente sipp01) ya está en otro ámbito L2, y si nos fijamos en la MAC origen del paquete, vemos que, efectivamente estamos logrando per-packet load balancing, es decir: WIN! Con las stats de wireshark se ve francamente bien:
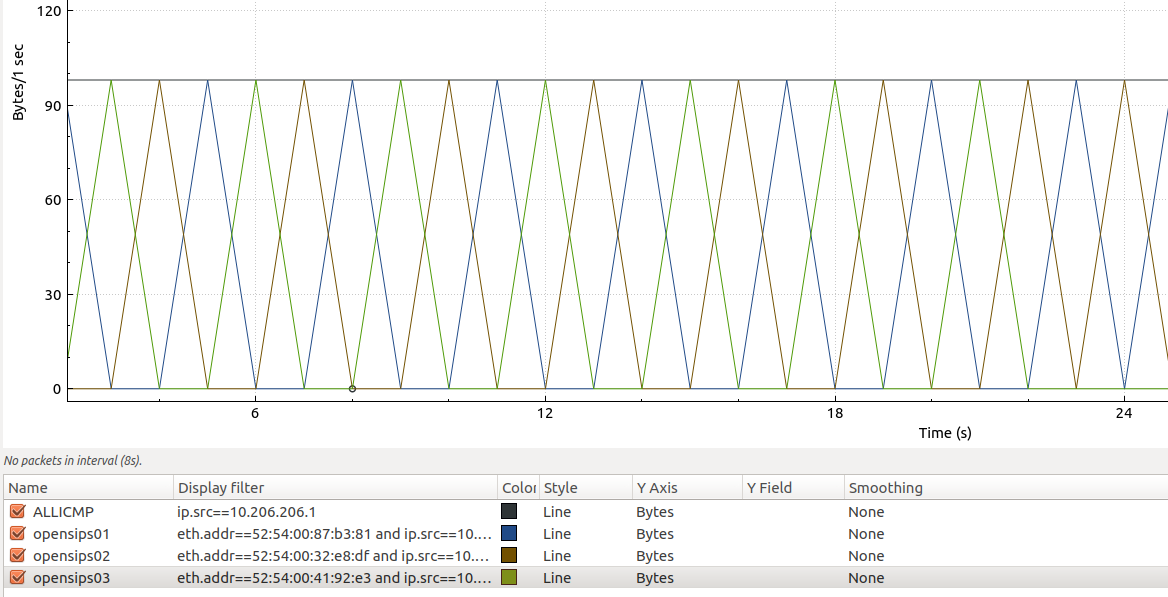
La gráfica superior muestra el total de respuestas echo reply (estamos pingando desde sipp01), las otras 3 gráficas son las diferentes posibles respuestas, siempre filtrando con la misma ip origen (10.206.206.1)
Recapitulando
Tenemos un entorno IP que ya nos permite hacer anycast real, sin balanceo por flujo ni nada, es decir, cada paquete IP (que realmente será luego un paquete SIP INVITE, 200 OK, etc …) está acabando en un nodo diferente.
Configurando OpenSIPS
Sobre este punto, destacar que seguiremos lo que nos proponen los desarrolladores de OpenSIPS en su último blog post, que realmente es el origen que nos ha animado a escribir este post, de nuevo la referencia para que la tengáis a mano:
Base del entorno
Lo que tendremos son:
- 3 nodos OpenSIPS con anycast, clusterer module
- 1 nodo de bbdd para la persistencia
- 2 clientes SIP simulados con SIPP
Primer paso: Configurar los listen’s de tipo anycast
Seguimos al pie de la letra el artículo y en todos los OpenSIPS:
listen=udp:10.206.206.1:5060 anycast
Configurando proto_bin / Clusterer module
Para este punto, lo que hacemos es escuchar en proto_bin (escuchamos en 0.0.0.0 para que sea más fácil copiar la configuración):
#### PROTO_BIN
loadmodule "proto_bin.so"
modparam("proto_bin","bin_port",5566)
#### CLUSTERER
loadmodule "clusterer.so"
modparam("clusterer", "db_url","mysql://opensips:[email protected]/opensips")
modparam("clusterer", "current_id", 1) # Diferente por nodo!
Como veis, os dejamos la contraseña porque la idea es luego subir a nuestro cloud las imágenes de las máquinas virtuales, por si alguien quiere probar todo esto sin tener que montarlo 😉
En cuanto a la tabla de clusterer:
MariaDB [opensips]> select * from clusterer; +----+------------+---------+------------------------+-------+-----------------+----------+----------+-------+-------------+ | id | cluster_id | node_id | url | state | no_ping_retries | priority | sip_addr | flags | description | +----+------------+---------+------------------------+-------+-----------------+----------+----------+-------+-------------+ | 1 | 1 | 1 | bin:10.205.205.11:5566 | 1 | 3 | 50 | NULL | NULL | Opensips01 | | 2 | 1 | 2 | bin:10.205.205.12:5566 | 1 | 3 | 50 | NULL | NULL | Opensips02 | | 3 | 1 | 3 | bin:10.205.205.13:5566 | 1 | 3 | 50 | NULL | NULL | Opensips03 | +----+------------+---------+------------------------+-------+-----------------+----------+----------+-------+-------------+
En el startup de OpenSIPS vemos claramente, por ejemplo en OpensSIPS01:
Mar 23 09:19:18 opensips01 /usr/sbin/opensips[803]: INFO:clusterer:handle_internal_msg: Node [2] is UP Mar 23 09:19:18 opensips01 /usr/sbin/opensips[804]: INFO:clusterer:handle_internal_msg: Node [3] is UP
Si apagamos el servicio en el nodo opensips03:
root@opensips03:/home/irontec# systemctl stop opensips
Vemos directamente en los logs, tras los diferentes reintentos:
mar 23 09:20:45 opensips01 /usr/sbin/opensips[809]: ERROR:proto_bin:tcpconn_async_connect: poll error: flags 1c mar 23 09:20:45 opensips01 /usr/sbin/opensips[809]: ERROR:proto_bin:tcpconn_async_connect: failed to retrieve SO_ERROR [server=10.205.205.13:5566] (111) Connection refused mar 23 09:20:45 opensips01 /usr/sbin/opensips[809]: ERROR:proto_bin:proto_bin_send: async TCP connect failed mar 23 09:20:45 opensips01 /usr/sbin/opensips[809]: ERROR:clusterer:msg_send: send() to 10.205.205.13:5566 for proto bin/7 failed mar 23 09:20:45 opensips01 /usr/sbin/opensips[809]: ERROR:clusterer:do_action_trans_1: Failed to send ping retry to node [3] mar 23 09:20:45 opensips01 /usr/sbin/opensips[809]: INFO:clusterer:do_action_trans_1: Maximum number of retries reached, node [3] is down mar 23 09:20:48 opensips01 /usr/sbin/opensips[809]: Timer Route - this is node opensips01
Siguiendo con el post de opensips: TM, Dialog
En todos los nodos:
# replicate anycast messages:
modparam("tm", "tm_replication_cluster", 1)
# replicate dialog profiles:
modparam("dialog", "profile_replication_cluster", 1)
Con eso hacemos que se repliquen las transacciones y diálogos
Gestionando cuando una transacción no la tiene el nodo que la recibe
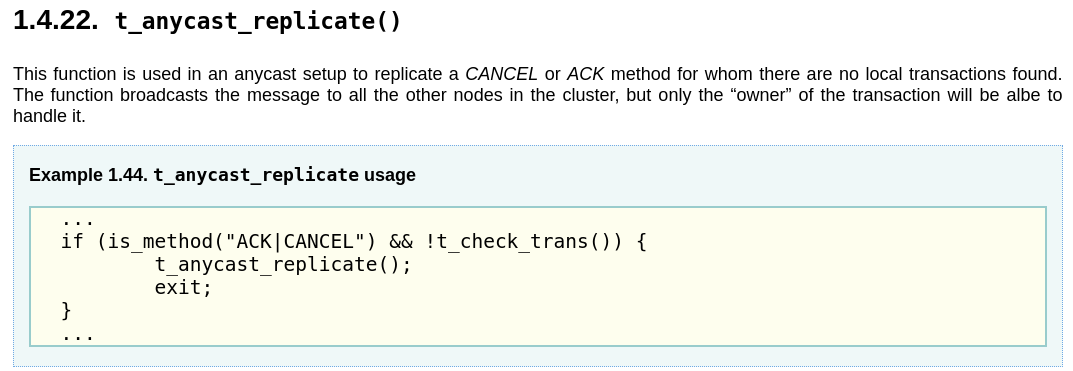
Principalmente, los desarrolladores de OpenSIPS han permitido con el módulo clusterer, que si una request no te pertenece, la puedas enviar por el proto_bin hacia el resto para que sea contestada por quien le pertenezca (en base a un tag que ponen en las via headers):
if (!loose_route()) {
if (!t_check_trans()) {
if (is_method("CANCEL")) {
# do your adjustments here
t_anycast_replicate();
exit;
} else if is_method("ACK") {
t_anycast_replicate();
exit;
}
}
}
El camino es hacer uso de la función t_anycast_replicate del módulo TM en 2.4:
Facilitando el debugging
Para facilitar el debugging, lo que haremos es que cada servidor tenga una server header diferente:
irontec@opensips01:~$ cat /etc/opensips/opensips.cfg | grep server_header server_header="Server: Opensips01" irontec@opensips02:~$ cat /etc/opensips/opensips.cfg | grep server_header server_header="Server: Opensips02" irontec@opensips03:~$ cat /etc/opensips/opensips.cfg | grep server_header server_header="Server: Opensips03"
Y, por otra parte, dado que el módulo dialog exporta stats, lo usaremos a modo de debugging, en todos los OpenSIPS:
timer_route[gw_update, 30] {
xlog("L_INFO","Timer Route - this is node opensips01");
xlog("Total number of active dialogs on this server = $stat(active_dialogs) \n");
xlog("Total number of processed dialogs on this server = $stat(processed_dialogs) \n");
}
Probando (estilo The Incredible Machine 😉 )
Si lanzamos una llamada desde el emisor al receptor, en la imagen de la arquitectura los de la izquierda, capturamos en este punto:

La idea es capturar en el interface de R1, para poder ver mac’s origen y destino, porque recordemos que la IP es la misma ! Estamos en anycast 😉
Callflow base
Iniciamos primero lanzando una llamada desde el emisor (que todavía no será SIPP, es sólo una prueba) hacia el receptor, que es el único registrado, lo que vemos por delante con SNGREP capturando en dicho interface:
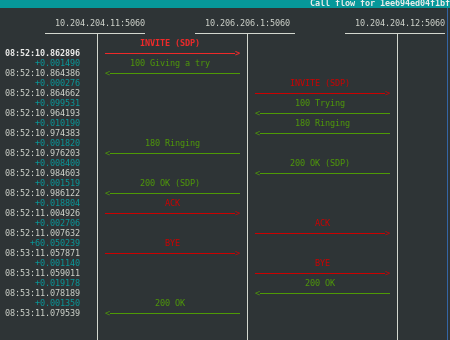
Es decir, lo que parece un flujo totalmente normal de A llama a B.
¿Y para esto tanto lío? Pues si, jijiji, tanto lío para verlo así de bonito, un flujo limpio. Si bajamos a más bajo nivel en la captura, al layer2:
Lo que se le ha mandado:
zgor@truenohome:~$ tcpdump -e -r pruebaparablog.pcap ip dst 10.206.206.1 reading from file pruebaparablog.pcap, link-type EN10MB (Ethernet) 08:52:10.862896 c4:00:33:ba:00:01 (oui Unknown) > 52:54:00:41:92:e3 (oui Unknown), ethertype IPv4 (0x0800), length 890: 10.204.204.11.sip > 10.206.206.1.sip: SIP: INVITE sip:[email protected] SIP/2.0 08:52:10.964193 c4:00:33:ba:00:01 (oui Unknown) > 52:54:00:32:e8:df (oui Unknown), ethertype IPv4 (0x0800), length 673: 10.204.204.12.sip > 10.206.206.1.sip: SIP: SIP/2.0 100 Trying 08:52:10.974383 c4:00:33:ba:00:01 (oui Unknown) > 52:54:00:87:b3:81 (oui Unknown), ethertype IPv4 (0x0800), length 689: 10.204.204.12.sip > 10.206.206.1.sip: SIP: SIP/2.0 180 Ringing 08:52:10.984603 c4:00:33:ba:00:01 (oui Unknown) > 52:54:00:41:92:e3 (oui Unknown), ethertype IPv4 (0x0800), length 1007: 10.204.204.12.sip > 10.206.206.1.sip: SIP: SIP/2.0 200 OK 08:52:11.004926 c4:00:33:ba:00:01 (oui Unknown) > 52:54:00:32:e8:df (oui Unknown), ethertype IPv4 (0x0800), length 473: 10.204.204.11.sip > 10.206.206.1.sip: SIP: ACK sip:[email protected]:5060 SIP/2.0 08:53:11.057871 c4:00:33:ba:00:01 (oui Unknown) > 52:54:00:41:92:e3 (oui Unknown), ethertype IPv4 (0x0800), length 501: 10.204.204.11.sip > 10.206.206.1.sip: SIP: BYE sip:[email protected]:5060 SIP/2.0 08:53:11.078189 c4:00:33:ba:00:01 (oui Unknown) > 52:54:00:32:e8:df (oui Unknown), ethertype IPv4 (0x0800), length 567: 10.204.204.12.sip > 10.206.206.1.sip: SIP: SIP/2.0 200 OK
Lo que que es interesante es que en esa captura se ven 3 MAC’s de destino:
- 52:54:00:41:92:e3
- 52:54:00:32:e8:df
- 52:54:00:87:b3:81
Esas 3 MAC’s corresponden a:
zgor@zlightng:~$ ip nei show | grep 10.205.205.1 10.205.205.11 dev vmbr1 lladdr 52:54:00:87:b3:81 REACHABLE 10.205.205.12 dev vmbr1 lladdr 52:54:00:32:e8:df REACHABLE 10.205.205.13 dev vmbr1 lladdr 52:54:00:41:92:e3 REACHABLE
Es decir, tenemos un diálogo iniciado con una transacción invite, que ha ha sido contestada con una respuesta temporal 1XX para finalmente una 200OK con su correspondiente ACK; cerrado finalmente con una transacción BYE, con su correspondiente respuesta 200 OK, todo ello enviado a nodos OpenSIPS diferentes!
Ilustrando el callflow con el Layer2
A continuación mostramos el mismo flujo pero detallando las requests y responses por mac address:
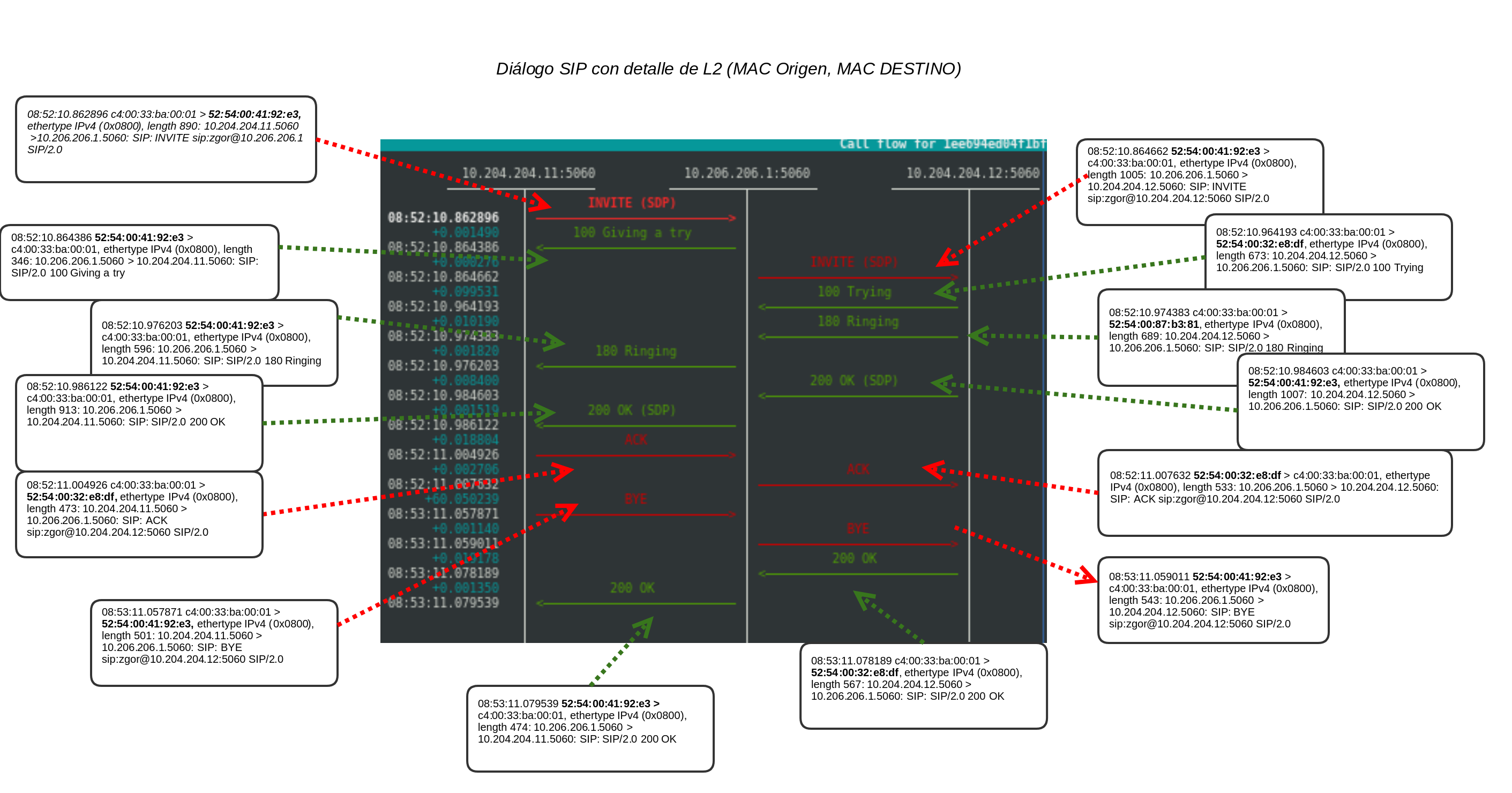
Principalmente, lo que queremos ilustrar es que es independiente el nodo destino a nivel físico, la transacción se gestiona correctamente. Si el nodo que la recibe no es el responsable de ella, al enviarla por el proto_bin la recibe quien sí lo es (en base a un tag en las cabeceras VIA se sabe tb) y éste sí que la gestiona.
Recapitulando:
- Podemos enviar tanto nuevas requests que inician diálogo como in-dialog request contra nodos diferentes, sin que esto afecte al tráfico SIP.
- Se puede por tanto entrar/salir del cluster por tareas de mantenimiento sin downtime de ningún tipo 😉
Viéndolo más gráficamente
Esta quizás sea la comparativa de imágenes que más evidencia esta situación, ambas cogidas con etherape (que ya usamos de alguna forma divertida hace tiempo):
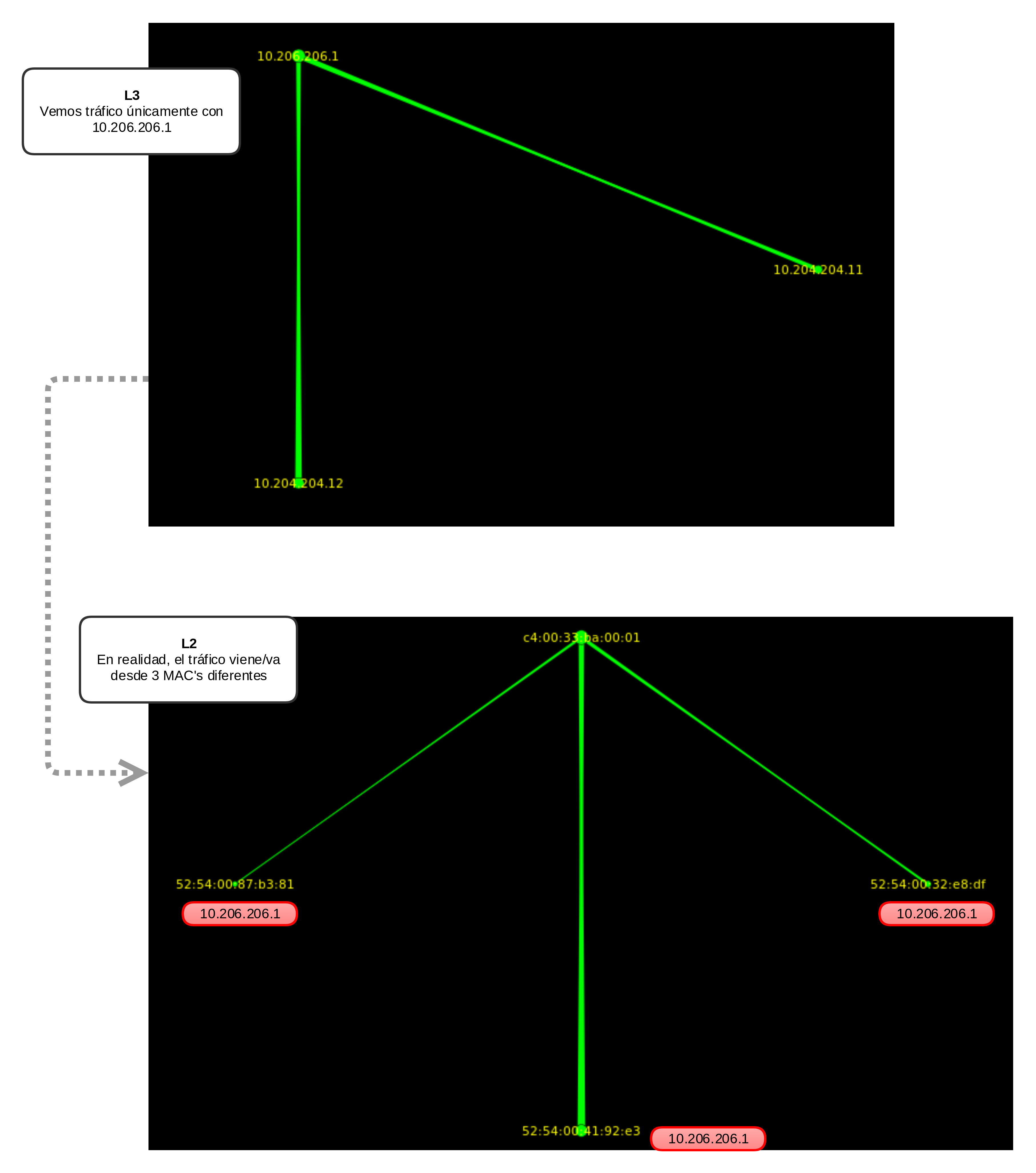
Concluyendo
Llegamos al final de este post, que recapitulando de forma express, si queréis montarlos un laboratorio de pruebas:
- Si queréis probar anycast, warning con montarlo con GNU/Linux, no es tan trivial per-packet load balancing, o al menos no lo hemos encontrando nosotros. Si que es cierto que con TEQL se puede, pero manualmente, no lo hemos visto desplegable fácilmente con Quagga/OSPF.
- OpenSIPS tiene que ser la nightly build si queremos desplegar por paquetes (2.4), sources.list: deb http://apt.opensips.org stretch 2.4-nightly
Y nada más que felicitar de nuevo a todo el equipo de OpenSIPS, gracias a su esfuerzo, los profesionales que opten por este tipo de soluciones como Proxy para exponerlo a los usuarios, a los operadores o como pieza interna necesaria en nuestra arquitectura podrán gracias a estas nuevas funcionalidades de la 2.4 actuar como activo/activo, con lo que las actualizaciones, scheduled downtimes, fast not dry run, son mucho más manejables 🙂
En lo respecta a implementaciones de la vida real, queremos destacar a nuestro partner Sarenet con su servicio Sarevoz, dónde llevan ya tiempo usando el concepto de anycast, trabajando conjuntamente con nuestro querido ExaBGP, Congratulations tb!
Por lo que comentan, en el OpenSIPS Submit se hablará de éste y de otras muchas cuestiones de interés!
1 Comentario
¿Por qué no comentas tú también?
Wow, excelente!.
Alberto Llamas Hace 8 años
Queremos tu opinión :)