Black Friday, Cyber Monday… Conceptos de los que hace tan sólo tres o cuatro años apenas habíamos oído hablar y que este año parecen haberse destapado definitivamente para asentarse en nuestros cerebros. Seguro que en vuestros trabajos lo habéis notado. De hecho, si entre los servidores que manejáis contáis con alguna tienda online, seguramente hayáis podido ver cómo la carga del servidor se incrementaba, e incluso cómo la base de datos no daba más de sí.
Si tus servidores no se han caído, ¡enhorabuena! Y si has sufrido ese problema, no hay mejor momento para aprender de lo sucedido e intentar hacer un análisis post black-friday.
Por más que intentemos controlar todos los aspectos de nuestros servidores, por distintas razones, hay que asumir que va a ser prácticamente imposible controlarlo todo. Y cuando creamos que lo tenemos controlado, seguro que algo pasará para darnos en los morros. Por eso, lo que hay que hacer es tener todos los datos posibles para poder realizar un análisis a posteriori de las crisis que hayamos tenido.
Y ahora puede que estéis pensando: «muy bien, ¿y qué es lo que tendría que tener?«. La respuesta podría ser: «logs, muchos logs». Gracias Captain Obvious, has hecho muy bien tu trabajo. Ahora en serio, ¿qué necesitamos? Vamos a intentar daros unos puntos de partida, pero como siempre, también esperamos vuestras opiniones en los comentarios.
Monitorización
Tenemos pendiente un artículo en el departamento de sistemas de Irontec que hable en profundidad sobre este tema y los distintos modos de llevarla a cabo, pero comenzamos con algunos puntos para ir abriendo boca.
En primer lugar, no podremos saber si el problema que hemos tenido en el servidor se debe a un servicio concreto si no podemos contextualizar los datos que tenemos. Es necesario compararlos con el estado del mismo servicio en otro momento del pasado. La situación sería: «estoy viendo que tengo 100 hilos de Apache, ¿es esto normal?» Pues lógicamente si no sabes cómo estaba ese Apache hace una semana o hace un mes, no vas a saber si es mucho, poco o se trata de la situación habitual. Por lo tanto, necesitamos hacer este trabajo previo.
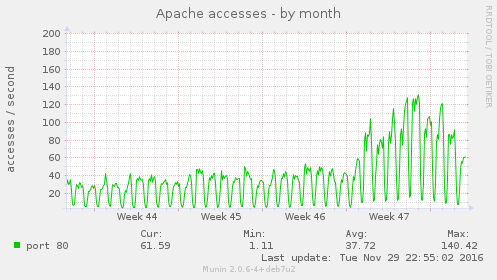
En la imagen superior podemos ver cuál era el comportamiento de la actividad de un servidor Apache cualquiera en las últimas semanas, y cómo el Black Friday ha hecho que se haya triplicado la actividad del mismo. Si no hubiésemos tenido estos datos previos, no podríamos haber sabido cuál era el incremento de accesos. Y todo esto al final lo vamos sabiendo en tiempo real.
Actuar rápido
 En situaciones como las de la semana pasada, hay que estar pendiente de nuestros servidores más que nunca. Puede que en cuestión de minutos la situación del servidor cambie, y pasemos de tener un servidor funcionando perfectamente a contar con un servidor inaccesible, un cliente cabreado y un jefe con mirada asesina.
En situaciones como las de la semana pasada, hay que estar pendiente de nuestros servidores más que nunca. Puede que en cuestión de minutos la situación del servidor cambie, y pasemos de tener un servidor funcionando perfectamente a contar con un servidor inaccesible, un cliente cabreado y un jefe con mirada asesina.
Ante situaciones como estas lo importante es intentar mantener la calma, analizar la situación real del servidor y priorizar en dónde vamos a poner nuestro esfuerzo para resolver el problema. Que no nos tiemble la voz en pedir ayuda a nuestros compañeros, que cuatro o seis ojos ven más que dos, y en situaciones desesperadas, hasta la idea más absurda puede ser una solución.
Cachear te puede va a salvar
Muchos de los servidores que utilizamos a diario, de una manera u otra, tienen algún sistema de caché. Otra cosa es que lo hayamos configurado para que la caché sea usada de manera más exhaustiva y durante más tiempo, o hayamos dejado los valores por defecto ?
Todos hemos aprendido que los cambios nunca se deberían hacer en producción directamente, pero tal como he dicho en el punto anterior, no tenemos tiempo que perder. En este caso, el cachear más de la cuenta puede salvarnos. De haber problemas, la solución es tan fácil como hacer un «flush» de las últimas cachés generadas.
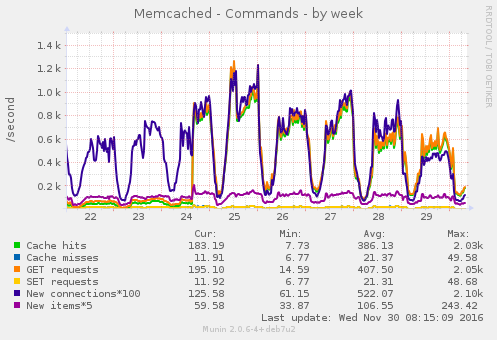
En la imagen se puede apreciar cómo darte cuenta que había un par de queries que no se estaban cacheando de manera adecuada, y arreglarlo, hace que Memcached llegue a cuadriplicar el tamaño que estaba usando. Y en la siguiente imagen vemos cómo efectivamente el ratio de «Caché hits» y las peticiones «GET» se incrementan para conseguir una eficiencia cercana al 100%. Todo gracias a ese cambio.
Alta disponibilidad y escalado horizontal
«¿Ha vuelto el Captain Obvious?» Dejad que me explique. Si no tenías un sistema en alta disponibilidad, este es el momento perfecto para que te plantees implementarlo. Si ya contabas con uno, ¿ha actuado tal como te esperabas? ¿Seguro que todos los servidores han recibido la misma carga? ¿Habría venido bien tener un servidor extra?
Un sistema en alta disponibilidad no garantizará que tu plataforma muera de éxito, pero al menos garantiza una mayor capacidad. Si nuestra infraestructura está pensada para escalarla horizontalmente de manera dinámica, entonces, si muere, morirá luchando: ¡¡¡ESTO ES ESPARTA!!!

El dibujo muestra una infraestructura en alta disponibilidad, que podríamos explicar así:
- Balanceo DNS: Nuestro dominio apunta a más de una dirección IP.
- Proxy HTTP (HAproxy): Las IPs llegan a unos HAproxy que se van a encargar de realizar un balanceo de carga entre los distintos nodos de Apache que tengamos.
- Servidores Apache: Los encargados de servir nuestro contenido web.
- Sistema de caché Redis: No sólo os va a servir para cachear información de la base de datos y para evitar accesos a ella, sino que también podéis guardar información de las sesiones de usuario del portal web, información temporal… Y todo ello montado en un cluster en distintos nodos donde la información se propagará automágicamente entre ellos. Recuerda, el acceso a RAM es mucho más rápido que a disco, por lo que evita usarlo en la medida de lo posible.
- Cluster MySQL: Almacenamos los datos en un cluster de MySQL, donde la información estará en cada uno de los nodos.
De esta manera, si tenemos hecho el trabajo previo de tener pensada la infraestructura, y nuestra plataforma está creada desde un primer momento para poder ser escalable, no nos debería suponer demasiado esfuerzo añadir nodos extra en momentos de alta carga.
Eso sí, conviene analizar el esfuerzo que ha realizado cada nodo para averiguar si el balanceo ha actuado tal como esperábamos, o hemos tenido algún nodo «vago«.
Conclusión
El pasado, pasado es, y ya no importa si tu servidor no aguantó la carga o si se produjeron fallos de implementación. Lo que importa ahora es aprender de lo sucedido, y ejecutar todas las acciones necesarias para que no vuelva a pasar. Para ello, sólo deberás tener una visión de futuro más amplia e intentar pensar la nueva infraestructura de tal forma que puedas hacer cambios en caliente en caso de necesidad o en momentos de alta carga.
El aumentar recursos al servidor no va a evitar que esta situación vuelva a ocurrir. Es mejor dedicar el esfuerzo a mejorar cada uno de los servicios que tienes y volverlos más eficientes para exprimir cada uno de los ciclos de CPU de los que dispones 😀
Queremos tu opinión :)