Hola de nuevo!
….. de nuevo, un poco de Docker, algo de networking, y sobre todo, ganas de enredar 😉 Porque como veréis, en esta ocasión, no tiene una aplicación clara directa en estos mundos de IT 😉
¿Qué hemos querido probar? Nos ha dado por buscar un poco las cosquillas al tema de containers y su supuesta súper alta densidad, de hecho, nada mejor que esta imagen cogida de ZDNET para empezar a hilar el tema:

Sentando la base de esta nueva aventura
Asi que por aquí, entre conversación de un tema y de otro, de vez en cuando le damos al networking 😉 , pero tb, de vez en cuando nos da por intentarle buscarle una aplicación no tan directa a nuestros clientes, proyectos y resto de galaxias digitales, simplemente porque nos gusta 🙂 Y, nos gusta tb recordar lo que nos enseñaron en la UNI / en el FP de turno, dónde hemos discutido muchísimo con varios profesores / expuesto nuestra apuesta firme por GNS3 y crear escenarios combinados de routers / VM’s y construirse un escenario grande.
El asunto principal con esa base, es que se construye tal que:
- Reflexionar sobre el escenario que queremos plantear (ilustrar un path múltiple, ilustrar un route summary, … plantear un bgp reflector ..)
- Montar el asunto con GNS3, o con VM’s (digo containers).
- Play.
- Probar, debugging, sentirse felices y orgullosos de nuestro nuevo logro.
Pero……. y si quisiéramos un poco de /dev/random en nuestras venas ? Poder buscar problemáticas y análisis a realizar sobre un escenario random siempre será mas sorprendente y curioso.
Es decir, no sería cómodo para un profesor que está explicando algo de networking a sus feroces alumnos que se le construya un escenario automáticamente, cada vez distinto, y tener que hablar, discutir, buscar las diferentes posibilidades con sus alumnos ? O claro está, tb puede ser para los que tienen mac address e ip’s por sus venas y tejido linfático jiji 😉
Y si de paso, le damos un push to the limits, para que sea un auténtico escenario, totalmente anti-kiss ? Vamos a ello 😉
Construyendo el juguete
Materiales

Container – from OpenClipart.org
Siguiendo la senda de los cazadores del rendimiento, planteemos el escenario con containers. Lo «bueno», de los containers, es que se olvidarán de todo una vez los apaguemos, con lo que el juguete tendrá pilas infinitas y será prácticamente irrompible.
Diseño
XWING Lego From OpenClipart.og 🙂
En cuanto al routing daemon, seguimos siendo fieles a Quagga, a pesar de que existan otras alternativas tb para GNU/Linux como:
En cuanto a las pre-built images, la verdad es que por Docker Hube aparecen unas cuantas Quagga Images automated build’s que tienen buena pinta, pero para nuestro caso, que lo que queremos hacer es algo totalmente random, y manipulable fácilmente on boot-time, nos ha encajado mas hacernos una image que hemos colgado tb por si os interesa. Básicamente es una Debian debootstrapeada, Quagga de repos oficiales y un micro-script boot.sh como entry-point.
Pegamento de piezas
Al ser totalmente olvidadizo, si jugamos a networking, su configuración debe por ser «self built» JIT style, nada mas arrancar. Con lo que a la hora de elegir el protocolo de routing dinámico que queramos usar, esta vez no se tratará de buscar lo compatible, lo que mejor se adapte, lo que nos permita crecer, sino que nuestro único objetivo será buscar el que sea más sencillo de scriptear inicialmente.
Esta claro que si queremos tener la versión pro de nuestro juguete podríamos tirar de servicios de discovery tipo ETCD (Que por cierto, tendremos que hablar algún día) y que se auto-construyan sesiones i/e BGP, pero no es el caso 🙂
Más allá del Docker Networking Model
La verdad es que la gente de Docker le está dando mucha caña al tema networking, pero por defecto no soportan multi-interface por container, se supone tb que es algo que, por diseño, no tendríamos que hacer, pero siguiendo la primera libertad de del software libre, queremos usarlo para lo que nos dé la gana, como este post, así que la alternativa a usar es Pipework que nos permite añadir una NIC a cada container fácilmente.
En esta entrada está realmente muy muy bien explicado 🙂
Auto-Creación de Instrucciones de juego
Bueno, estamos hablando mucho de escenario grande, dinámico, y random, pero cómo lo vemos? Tenemos que entrar a cada container, sacar su tabla arp, comprarar, hacer diffs, pings y pintar ? Si hombre, y el juguete acabará en la ría al primer día 😉
La verdad es que es admirable la comunidad open source, basta con necesitar algo tal: «creador en base a script de gráficos de unión entre nodos – sencillo, hello world en 30 secs y que quede mas o menos bien«(XD), como era nuestro caso y tachánnnnn ya había algo: el flamante GRAPHVIZ , de hecho, seguramente hemos visto decenas de veces gráficos auto-generados, de forma tan sencilla como partir de un script (ficherogv.gv) tipo:
digraph testing {
rankdir=LR;
node [shape = ellipse]; NET_0 NET_1 NET_2;
node [shape = octagon]; R_1 R_2 R_3 R_4 R_5;
node [shape = circle];
R_1 -> NET_0 [ label = "" ];
R_1 -> NET_1 [ label = "" ];
R_1 -> NET_2 [ label = "" ];
R_2 -> R_3 [ label = "" ];
R_3 -> NET_1 [ label = "" ];
R_4 -> R_3 [ label = "" ];
R_4 -> NET_2 [ label = "" ];
R_5 -> NET_0 [ label = "" ];
}
Ejecutamos tal que:
dot -Tpng -oblog.png ficherogv.gv
y voiláaaa, obtenemos algo tipo:
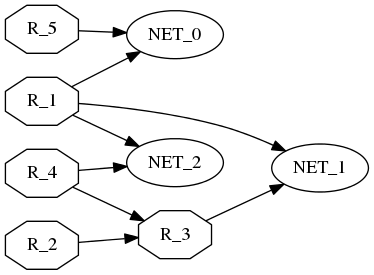
Como véis, es fácilmente scripteable crearse una pseudo-esquema de lo que hayamos construido como escenario de red. En este ejemplo las flechas tienen dirección, no hay colores y tal, para dejarlo un poco mas presentable, hay muchas opciones dentro de cada tipo de elemento del fichero DOT.
Scripteando
Un poco de bash scripting por las mañanas siempre sienta bien 😉 Si alguno de las mesas cercanas lo quiere portar a Perl, bienvenido sea 😉 De hecho, aquí lo tenéis, si queréis añadirle NETEM en plan chili picante, o un iptables match probability, bienvenidos seáis todos !
De forma directa, el script que hemos hecho, quitando sanity checks y «limpiador» de entorno, nos quedaría tal que:
#!/bin/bash
# Definicion de escenario
# ==========================
TOTALROUTERS=20
TOTALBRIDGES=6
MINROUTERINTERFACES=1
MAXROUTERINTERFACES=3
NETBASE="192.168."
# Fichero con el escenario en lenguaje DOT:
FICHEROGV="/tmp/test.gv"
# PNG Generado:
FICHEROPNG="/tmp/test.png"
# KILLING ALL CONTAINERS
# =====================
echo "Killing all containers in 3 segs - press control C to cancel!"
sleep 3
docker ps -a -q | wc -l
docker rm -f $(docker ps -a -q)
# DIGRAPH MAIN HEADERS:
# =====================
echo "digraph testing {" > $FICHEROGV
echo size="40,10"; >> $FICHEROGV
echo "rankdir=LR;" >> $FICHEROGV
# NETWORK IBRIDGES CREATION
# ================
LISTABRIDGES=$(seq 1 $TOTALBRIDGES)
echo -n "node [shape = ellipse , style=filled, fillcolor=red];" >> $FICHEROGV
for ACTUAL in $LISTABRIDGES;do
echo "# CREATING NETWORK: $ACTUAL"
echo -n " NET_$ACTUAL " >> $FICHEROGV
brctl addbr brtesting$ACTUAL 2>/dev/null
ifconfig brtesting$ACTUAL up
LASTIP[$ACTUAL]=1
done
echo ";" >> $FICHEROGV
# ROUTER CREATION
# ===============
LISTAROUTERS=$(seq 1 $TOTALROUTERS)
for ACTUAL in $LISTAROUTERS;do
echo "# CREATING ROUTER: $ACTUAL"
echo "node [shape = octagon, style=filled, fillcolor=white]; R_$ACTUAL ; " >> $FICHEROGV
docker run --privileged --net=none -d --name=router$ACTUAL zetagor/quagga boot.sh
INTERFACES=$(shuf -i $MINROUTERINTERFACES-$MAXROUTERINTERFACES -n 1)
echo " $INTERFACES interfaces needed"
LISTAINTERFACES=$(seq 1 $INTERFACES)
GENERADOS=""
for IFACEACTUAL in $LISTAINTERFACES;do
FOUND=0;
# Bucle, por si le hemos conectado ya a la misma red
while [ $FOUND == 0 ]; do
NET=$(shuf -i 1-$TOTALBRIDGES -n 1)
if [[ ${GENERADOS[*]} =~ $NET ]];then
# Need to generate again
FOUND=0
else FOUND=1
GENERADOS="$GENERADOS $NET"
fi
done
IP="$NETBASE$NET.${LASTIP[$NET]}/24"
echo " NET $NET - IP: $IP - bridge brtesting$NET"
TEMP=${LASTIP[$NET]}
TEMP=`expr $TEMP + 1`
LASTIP[$NET]=$TEMP
pipework brtesting$NET -i eth$NET router$ACTUAL $IP
if (( $NET < $TOTALBRIDGES / 2 )); then
echo " R_$ACTUAL -> NET_$NET [ label = \"\" dir = \"none\"];" >> $FICHEROGV
else
echo " NET_$NET -> R_$ACTUAL [ label = \"\" dir = \"none\"];" >> $FICHEROGV
fi
# BLACK MAGIC (para que el Grafico quede bien, flechas virtuales)
if (( $ACTUAL % 5 == 0 )); then
echo " R_$ACTUAL -> R_$(expr $ACTUAL - 1) [ style=invis ];" >> $FICHEROGV
fi
# / fin black magic
done
done
echo "}" >> $FICHEROGV
# GENERACION FINAL del PNG del escenario
dot -Tpng -Gsize=9,15\! -Gdpi=100 -o$FICHEROPNG $FICHEROGV
como véis, básicamente lo que hacemos es construir en paralelo el fichero de GraphViz y el escenario, para al final, tener el PNG generado y el escenario montado.
Por poner un poco de explicaciones:
- Las primeras líneas son para configurar el escenario, cuantos routers queremos, interfaces de red, redes y tal
- En el primer bucle únicamente creamos los bridges necesarios, uno por cada red.
- El segundo bucle es un pelín mas complicado, pero realmente lo único que hacemos es:
- Lanzar un container por cada router.
- Por cada cada router, conectarle tantos interfaces como aleatoriamente le hayan tocado (evitando tener a la misma red varios).
- Y controlar las IP’s que hemos ido asignando.
Primeras partidas
Parametrizando con 10 routers inicialmente, obtenemos algo tipo:
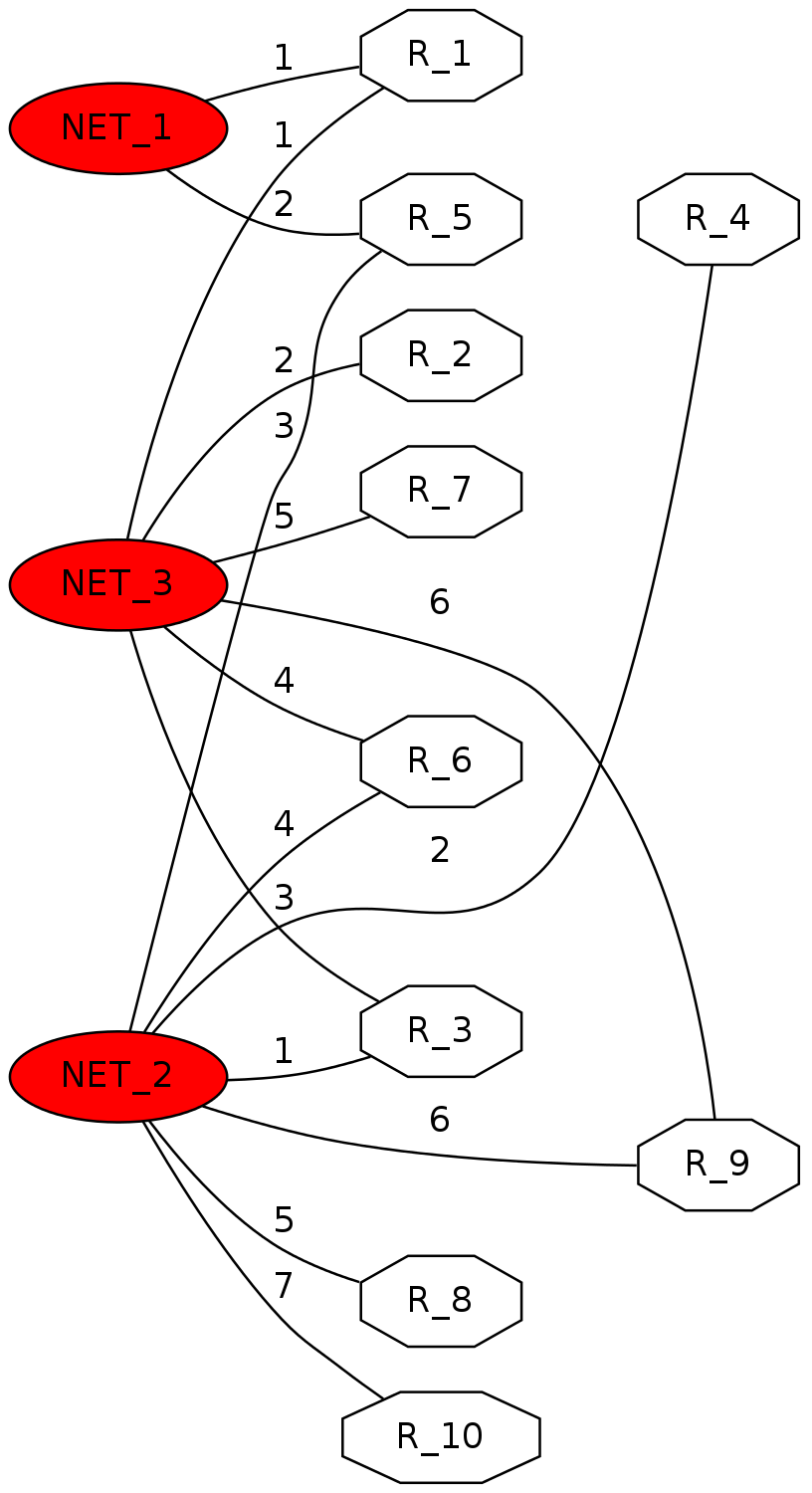
Sobre este esquema, si cogemos por ejemplo router10(192.168.2.7), para llegar a router7(192.168.3.5):
root@zgordockerquagga:~# docker exec -it router10 vtysh Hello, this is Quagga (version 0.99.22.4). Copyright 1996-2005 Kunihiro Ishiguro, et al. router10# traceroute 192.168.3.5 traceroute to 192.168.3.5 (192.168.3.5), 30 hops max, 60 byte packets 1 192.168.2.1 (192.168.2.1) 0.121 ms 0.028 ms 0.030 ms 2 192.168.3.5 (192.168.3.5) 0.063 ms 0.039 ms 0.061 ms
Es decir, pasa por router3 (192.168.2.1), que enlaza ya directamente con dicha red, y de hecho, lo ha aprendido vía rip:
router10# show ip route 192.168.3.5 Routing entry for 192.168.3.0/24 Known via "rip", distance 120, metric 2, best Last update 00:05:25 ago * 192.168.2.1, via eth2
La diversión aumenta considerablemente si creamos escenarios con mas redes y mas routers, pongamos 6 redes y 25 routers, con máximo 3 ifaces por router, obtendremos, totalmente random:

Si cogemos este ejemplo y buscamos routers aislados, por ejemplo R17 y R13:
router13# traceroute 192.168.5.2 traceroute to 192.168.5.2 (192.168.5.2), 30 hops max, 60 byte packets 1 192.168.3.1 (192.168.3.1) 0.140 ms 0.027 ms 0.024 ms 2 192.168.1.2 (192.168.1.2) 0.114 ms 0.079 ms 0.065 ms 3 192.168.5.2 (192.168.5.2) 0.068 ms 0.045 ms 0.045 ms
Es decir, pasa por R12, así que, sin mas miramientos:
docker kill router12
y de nuevo, sin esperar los timers de RIP:
router13# traceroute 192.168.5.2 traceroute to 192.168.5.2 (192.168.5.2), 30 hops max, 60 byte packets 1 * * * 2 * * * 3 * * * 4 * * * 5 * * * 6 * * * 7 * * * 8 * * * 9 * * * 10 * * * 11 * * 192.168.3.2 (192.168.3.2) 2998.200 ms !H
y tras la convergencia de rutas:
router13# traceroute 192.168.5.2 traceroute to 192.168.5.2 (192.168.5.2), 30 hops max, 60 byte packets 1 192.168.3.3 (192.168.3.3) 0.144 ms 0.032 ms 0.030 ms 2 192.168.6.3 (192.168.6.3) 0.066 ms 0.034 ms 0.034 ms 3 192.168.7.6 (192.168.7.6) 0.062 ms 0.075 ms 0.073 ms 4 192.168.5.2 (192.168.5.2) 0.151 ms 0.059 ms 0.058 ms
Es decir: R24 => R16 => R23 => R17
¿Habría otro camino mejor? ¿No son muchos saltos? … os dejo que sigáis las flechas jijiji
Jejeje, y todo esto sin planearlo, simplemente: ./constructor.sh
Como modelo de aprendizaje, creemos que sobre esta base se pueden construir escenarios mas complicados tipo añadiendo metrics random en la config de inicio creada por boot.sh, y que las cuestiones a solucionar sea adivinar la config de un router en base a las rutas que van seleccionando los diferentes routers 🙂
Si lo vamos complicando un poco, la verdad es que el mapa auto-creado no es tampoco del todo visible, pero mas o menos se puede entender, aquí va un escenario recién disparado con 50 routers, 9 redes, 3 enlaces máximos:

Límite técnico
De forma rápida, con el script anterior, que estaba pensado por diseño para 254 IP’s por red máximo, hemos lanzado a tope y la verdad es que el anfitrión aguanta bien. Así que con un par de cambios en el script (cambiando todas las nets a /16 y saltando de tercer octeto), ha bastado para poder generar bien el escenario.
Sinceramente, la primera vez que le dimos, como somos de Bilbao, lo pusimos con sin límite, y, con total sinceridad: Estalló por todos lados. Dicen que hace no tanto tiempo se supero la barrera de las 512k rutas, así que, que menos aquí que construirnos un mini-internet, digamos del 10% como poco no ? A una media (al azar, sinceramente) de 10 rutas por router, serían 512k * 0,1 * 0,1 = 5K ! Y la verdad, es que como comentamos a continuación, no nos hemos quedado lejos jijiji XDDD (es broma)
Bueno, tampoco es todo jugar por aquí 😉 Hay que poner alguna gráfica de rendimiento en plan consultores expertos 😛 Así que nos hemos permitido lanzar este otro script en paralelo para ir obteniendo métricas, así como tunear el clásico /etc/security/limits.conf y asuntos similares habituales , algo del tipo:
#!/bin/bash
echo "TOTALCONTAINERS,USR,NICE,SYS,IOWAIT,IRQ,SOFT,STEAL,GUEST,IDLE"
while [ 1 ];do
CONTAINERS=$(docker ps -q | wc -l)
echo -n "$CONTAINERS,"
mpstat 10 1 | grep Media | awk '{printf "%s|%s|%s|%s|%s|%s|%s|%s|%s\n", $3,$4,$5,$6,$7,$8,$9,$10,$11}' | sed s/','/'.'/g | sed s/'|'/','/g
sleep 15
done
… que nos genera un output fácilmente copy-paste a donde sea para sacar gráficas 😉
root@zgordockerquagga:~# bash stats.sh TOTALCONTAINERS,USR,NICE,SYS,IOWAIT,IRQ,SOFT,STEAL,GUEST,IDLE 0,0.03,0.00,0.01,0.00,0.00,0.00,0.01,0.00,99.95 0,0.00,0.00,0.03,0.02,0.00,0.00,0.00,0.00,99.95 1,0.34,0.00,0.56,0.03,0.00,0.00,0.05,0.00,99.02 7,0.40,0.00,0.68,0.50,0.00,0.00,0.05,0.00,98.37 13,0.55,0.00,0.85,0.05,0.00,0.01,0.06,0.00,98.48 19,0.59,0.00,1.01,0.04,0.00,0.00,0.07,0.00,98.28 26,0.52,0.00,0.77,0.03,0.00,0.01,0.04,0.00,98.63 32,0.55,0.00,0.93,0.04,0.00,0.02,0.05,0.00,98.41 37,0.61,0.00,1.07,0.05,0.00,0.04,0.06,0.00,98.16
El host en concreto, dónde estamos ejecutando Docker Engine, es a su vez una MV sobre KVM, sí, rizando de nuevo el rizo, pero es simplemente porque es súper cómodo así 🙂 Ni nos hemos levantado 😉 Le hemos dado 10vCores, 30Gigs RAM (aunque nos sobran 25 de 30 sinceramente jiji)
Sin querer hacer que estalle del todo, como quien busca Google en Google, hemos llegado fácilmente a:
2971 containers !
Y para ver que la gran malla se distribuye bien y por tanto, confirmar que RIPD está haciendo su work, varias ejecuciones RANDOM, como no podía ser de otra forma lo confirman:
root@zgordockerquagga:~# docker exec -it router$(shuf -i 1-2971 -n 1) vtysh -c 'show ip rip' | grep -c 'R(n)' 28 root@zgordockerquagga:~# docker exec -it router$(shuf -i 1-2971 -n 1) vtysh -c 'show ip rip' | grep -c 'R(n)' 28 root@zgordockerquagga:~# docker exec -it router$(shuf -i 1-2971 -n 1) vtysh -c 'show ip rip' | grep -c 'R(n)' 28
Es decir, ejecutamos de forma random en cualquiera de nuestros 2971 routers lanzados un vtysh que ejecuta un show ip rip y contamos las rutas que conocen por RIP, y todos conocen las mismas 🙂
Siguiendo con esta prueba, hemos podido sacar nuestras gráficas que no podían faltar:
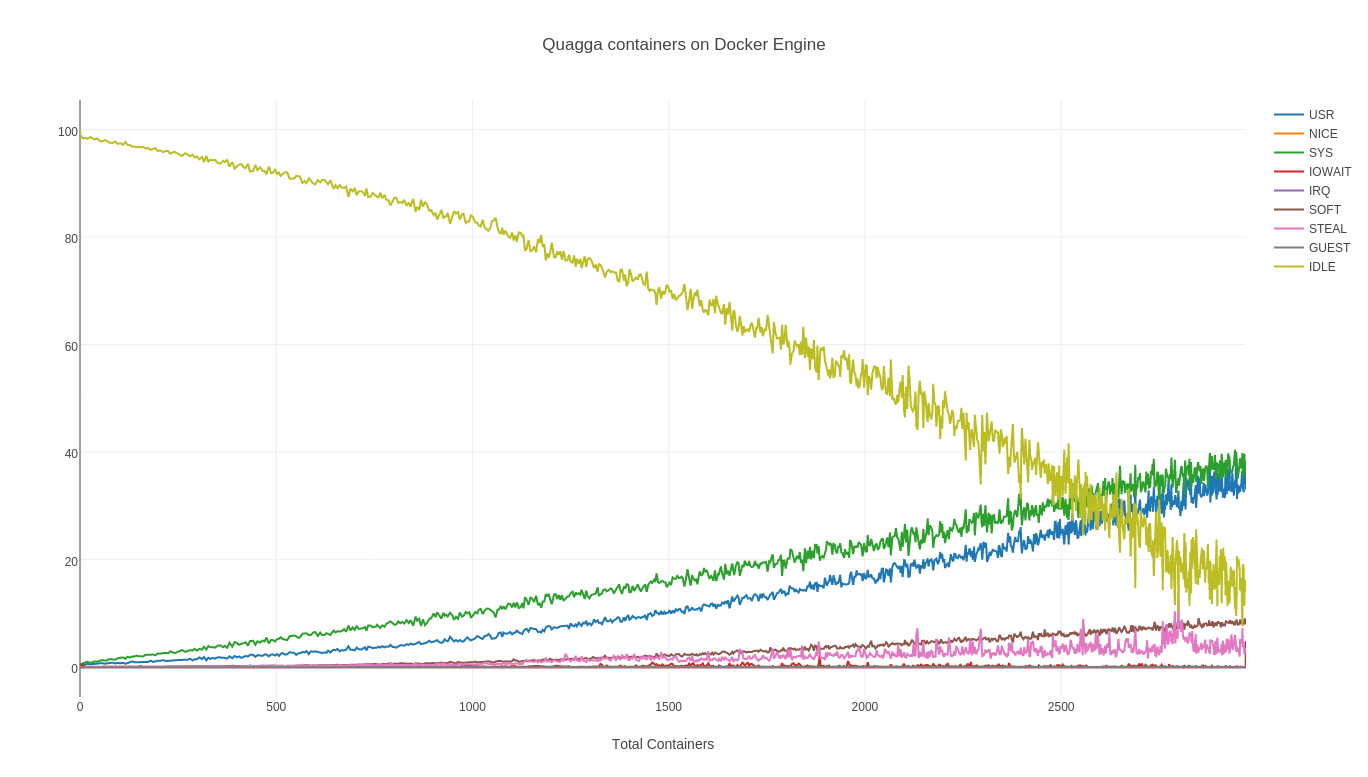
Obviamente, estos containers son muy ligeritos, realizan solo envíos de paquetes RIP, recepción, consulta tabla kernel, actualización, propagación … es decir, prácticamente todo será I/O blocks hasta recibir por red, un timer cada 30 segs (default rip) y poco más, es decir, no hay que buscar aquí el entorno con NGINX, cientos de sesiones de usuario, Node.JS dándolo todo e instancias de MySQL Réplicas de lectura auto-disparadas, esto es lo que es, y nos gusta probarlo así :D)
Más allá de estas pruebas iniciales
Lo comentado antes … siguiendo esta metodología, se puede ir complicando:
- Añadir IP’s de loopback (no hemos conseguido todavía tener dummy0 en containers).
- Utilizar otro protocolo tipo OSPF o liarse un poco mas la manta y auto-crear sesiones BGP con un random de IP’s que respondan en las redes? El tema del AS … sin tirar servicios de discovery, podría ser algo en base a MAC’s o similar.
- Poner dos entry-points externos en dos VM’s bridgeadas (o containers 😉 ) a todo esta gran malla de 1000 y pico routers y hacer pruebas de conexiones tcp, tirar routers, ver lo que tarda en la «gran convergencia».
Nada más por hoy 🙂 Como véis, un poco «especial» esta temática, aunque de verdad creemos que el enfoque de que el escenario se construya random vs tener que pensar posibles problemas y crear un escenario ad-hoc/express puede ser una vía interesante de exploración 😉 A parte de haber lanzando 2971 routers y quedarnos tanto contentos 🙂
Hasta otra!
1 Comentario
¿Por qué no comentas tú también?
Sois brutales !
Rosa Hace 11 años
[…] a Massive Attack de fondo, Inertia Creeps, slowlyyyyyyyy ? No queremos que estalle todo, como aquella vez que quisimos simular todo el bgp de internet con Docker […]
Warriors of the net: IP Channel over Multipath TCP | Blog Irontec Hace 10 años
[…] (Telnyx – sponsor del OpenSIPSSummit2018), con quien tuvimos la ocasión de salir a cenar y compartir experiencias de containers, rutas y la vida entre Mallorca y Chicago […]
OpenSIPS Summit Amsterdam 2018 - Blog Irontec Hace 8 años
Queremos tu opinión :)