¡Buenas!
Año nuevo, desafíos nuevos que le dicen 😉 Esta vez, algo de networking directo al cerebro, bastante Warriors of the Net 😉 (y valga este enlace al vídeo indispensable para entonar la velada), en dosis a ritmo, como si fuera Requiem for a Dream.
Para sentar las bases un poco del asunto y sin querer faltar al respeto a ningún lector:
- Si tenemos un río y queremos pasar cajas al otro lado, tendremos que tener un puente.
- Si hacemos un puente ancho, podremos pasar muchas cajas a la vez. Si hacemos uno más estrecho, pues menos cajas.
Es decir, si hablamos de la nic del host, sería hablar de si vamos a Fast Ethernet, Gigabit Ethernet o, ya en el 2016 que estamos, a 10 Gigabit Ethernet. Y lo mismo para las uniones entres switches o accesos WAN que tengamos.
¿Pero qué pasa si tiramos 4 puentes? ¿Movemos entre las orillas con 4 veces más de capacidad total? La respuesta, en los escenarios más comunes: depende del destino.
- Si es para mover cajas entre muchos orígenes / destinos variados estadísticamente: la respuesta es ¡si!
- Si es para mover siempre un mismo flujo, la respuesta es no: los elephant flow no se dividen inter puente. Cada elefante pasará, troceado o licuado por su puente, sí o sí.
En el mundo del networking, estaríamos hablando de Etherchannel (Cisco) / LACP (802.3ad IEEE), que consiste en agregar / balancear / redundar el tráfico entre dos layer2/3 devices de forma controlada, también conocido como bonding en los mundos más de GNU/Linux, por denominarse así en el propio kernel, así como su interface en /proc de información de status.
El protocolo LACP, francamente muy bien comentado aquí, incluido el salto a 802.1AX, es generalmente el más utilizado, desde pequeñas redes a grandes entornos, tanto para redundancia y tolerancia a fallos, como para crecer en ancho de banda. Podríamos exponer lo siguiente, para hilar un poco este post:
Un pc1 conectado a un SW, a Gigabit (para que no sea el cuello de botella), que a su vez está conectado a otro switch por medio de un LAG de 2x FastEthernet, dónde hay un pc2 conectado a Gigabit, es decir, más o menos este esquema:
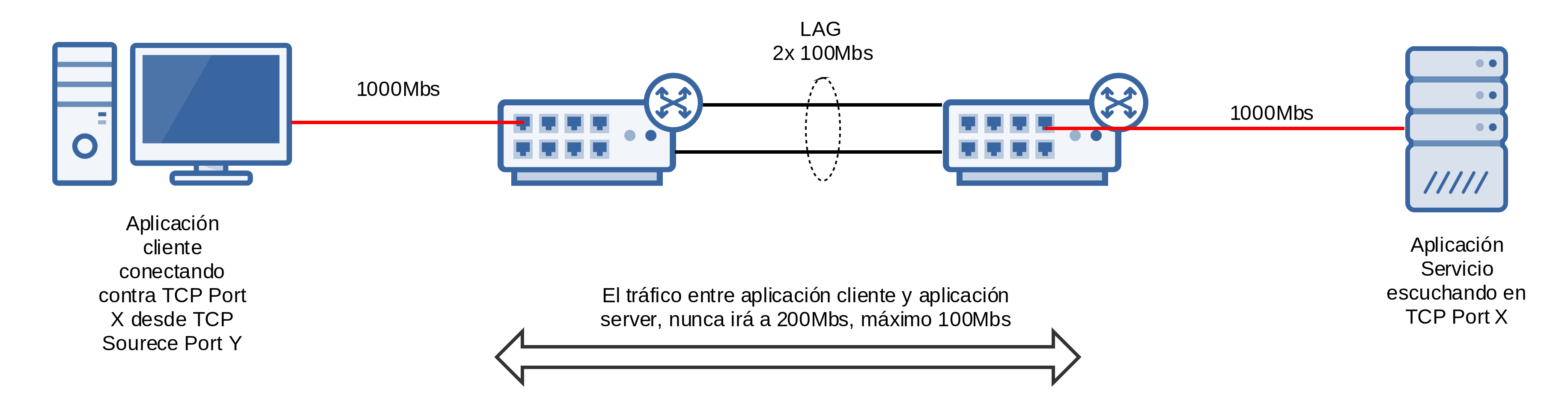
Lo que podemos establecer es:
- Si mediante una conexión tcp copiamos un fichero de pc1 a pc2 (http, ftp, sftp, …): La velocidad nunca será mas de 100Mbs.
En cambio, si escalamos, simulando que ese enlace es realmente una fibra que va entre 2 sedes por ejemplo y plantamos pc’s como setas:
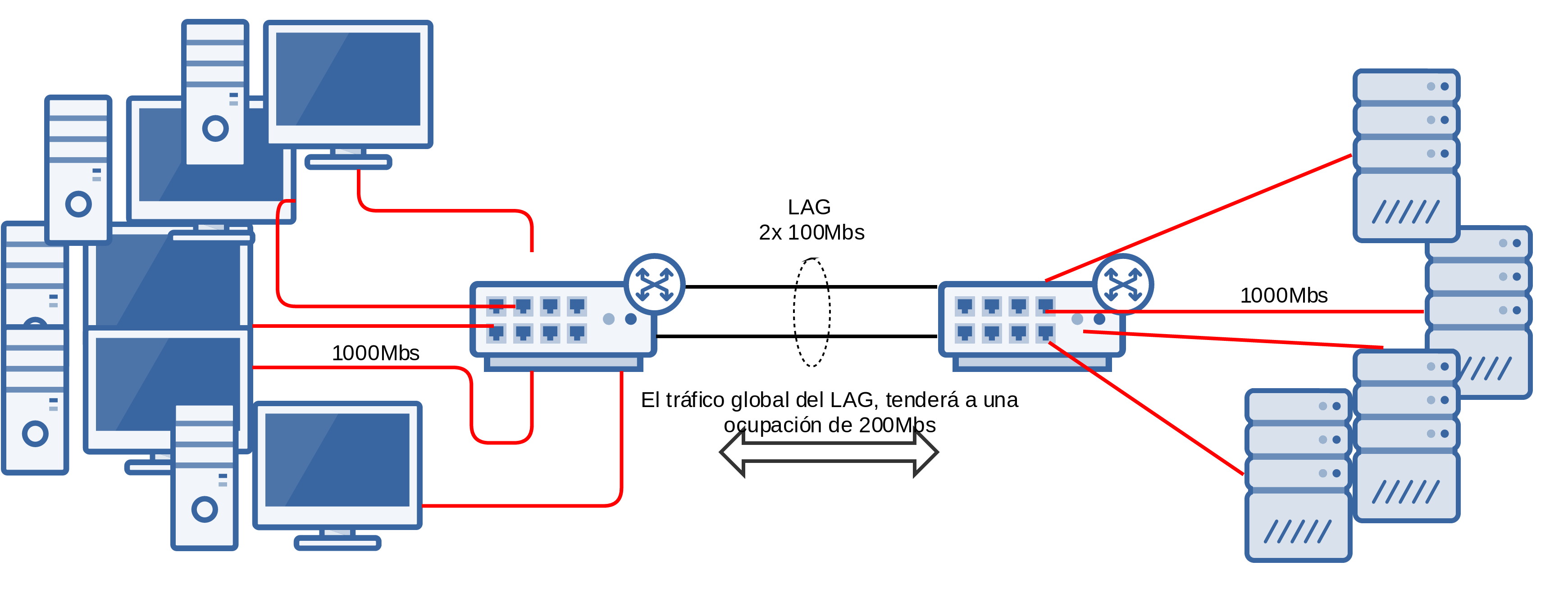
Lo que podemos establecer:
- Si hay comunicación entre todos los elementos, estadísticamente estaremos cerca de la ocupación 200Mbits total en el LAG.
Esto es lo conocido, y generalmente peleado en el área de administración de sistemas, donde incluso la pelea se encamina o bien vía iSCSI MPIO, o incluso NFS 4.1 Session Trunking o directamente 10GE evitando todos esos complejos escenarios de networking, estando las nic’s nuevas poco a poco cada vez más baratas.
Pasito a pasito: Montando un mini LAG local
De cara a ir planteando nuestro asalto, construimos primero un entorno de pruebas con un par de máquinas, pasito a pasito. Podemos relajar el push inicial, cambiando a Massive Attack de fondo, Inertia Creeps, slowlyyyyyyyy 😉 No queremos que estalle todo, como aquella vez que quisimos simular todo el bgp de internet con Docker XD
En esta ocasión, como excepción: máquinas físicas, así nos ahorramos posibles dudas de VirtIO, limitaciones o bridges virtuales, physical layer. Algo así como:
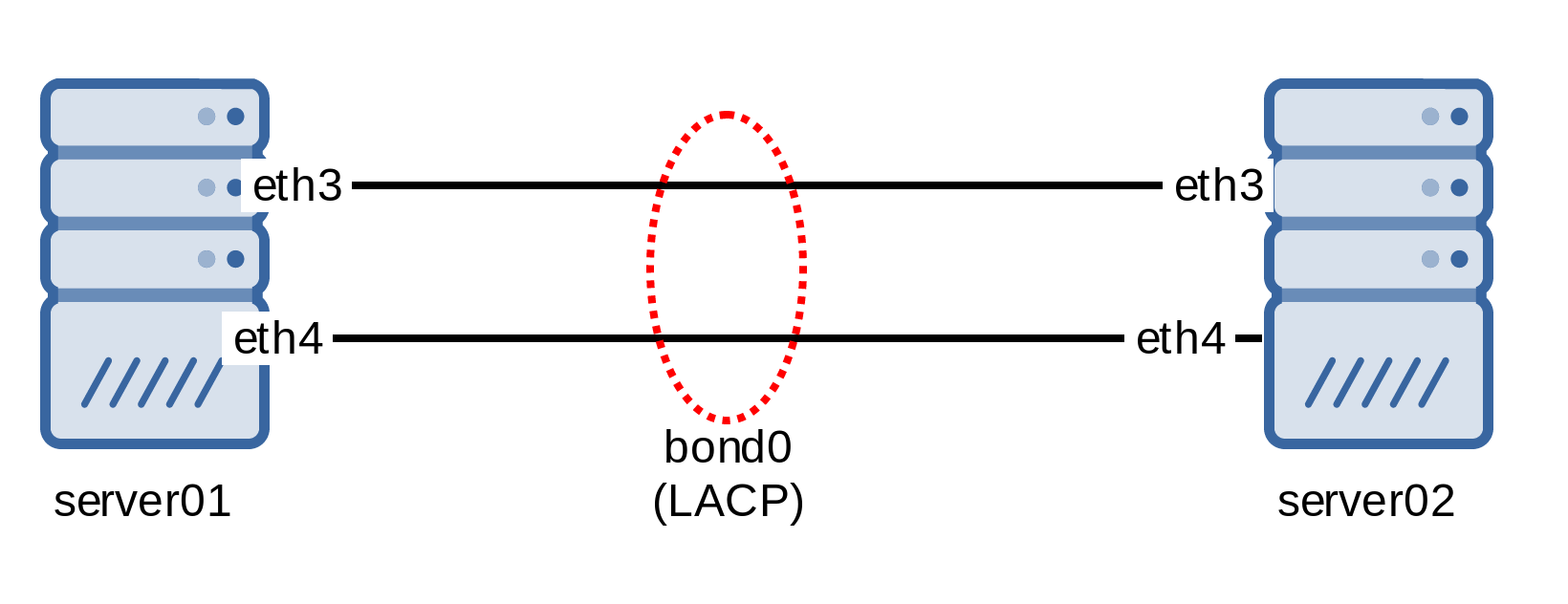
Para la configuración en GNU/Linux, es independiente de la distro, ya que la funcionalidad está en el propio kernel driver para bonding, aunque las aplicaciones de usuario que invocan la config si que nos interesa tener, en Debian’s like sería instalar el paquete: ifenslave – configure network interfaces for parallel routing (bonding)
En lo que respecta la definición de los interfaces en boot-time, varía de distro a distro también, en Debian sería, a modo de ejemplo un fichero /etc/network/interfaces tal que:
auto bond0
iface bond0 inet static
address 10.92.92.1
netmask 255.255.255.252
network 10.92.92.0
bond-mode 4
bond-miimon 100
bond-downdelay 200
bond-updelay 200
slaves eth1 eth2
En este ejemplo, cabe destacar:
- bond-mode: Mode 4 es 802.3ad (LACP)
- bond-miimon: Cada cuanos millisecs se mira el estado del enlace.
- bond-downdelay /updelay: Delay en agregar/desagrear un enlace.
Para comprobar que se ha levantado correctamente:
root@mpath01:~# cat /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: IEEE 802.3ad Dynamic link aggregation Transmit Hash Policy: layer2 (0) MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 200 Down Delay (ms): 200 802.3ad info LACP rate: slow Min links: 0 Aggregator selection policy (ad_select): stable Active Aggregator Info: Aggregator ID: 1 Number of ports: 2 Actor Key: 9 Partner Key: 9 Partner Mac Address: 00:11:6b:67:bc:ce Slave Interface: eth3 MII Status: up Speed: 100 Mbps Duplex: full Link Failure Count: 1 Permanent HW addr: 00:11:6b:67:bb:8b Aggregator ID: 1 Slave queue ID: 0 Slave Interface: eth4 MII Status: up Speed: 100 Mbps Duplex: full Link Failure Count: 1 Permanent HW addr: 00:11:6b:67:b0:54 Aggregator ID: 1 Slave queue ID: 0
De este output, poco que destacar: están los dos interfaces correctamente añadidos.
Probando el enlace LAG(LACP)
Utilizando el archiconocido iperf, obtenemos resultados sostenidos tales que:
TCP
root@mpath01:~# iperf -t 60 -c 10.92.92.2 ------------------------------------------------------------ Client connecting to 10.92.92.2, TCP port 5001 TCP window size: 85.0 KByte (default) ------------------------------------------------------------ [ 3] local 10.92.92.1 port 43642 connected with 10.92.92.2 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-60.0 sec 675 MBytes 94.3 Mbits/sec
UDP (mismos resultados)
Con UDP obtenemos el mismo resultados, pero sacamos el dato para dejarlo a la vista para la siguiente sección 😉
root@mpath01:~# iperf -u -c 10.92.92.2 -b 1000M ------------------------------------------------------------ Client connecting to 10.92.92.2, UDP port 5001 Sending 1470 byte datagrams UDP buffer size: 208 KByte (default) ------------------------------------------------------------ [ 3] local 10.92.92.1 port 33655 connected with 10.92.92.2 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 114 MBytes 95.9 Mbits/sec [ 3] Sent 81541 datagrams [ 3] Server Report: [ 3] 0.0-10.0 sec 114 MBytes 95.7 Mbits/sec 0.456 ms 0/81540 (0%) [ 3] 0.0-10.0 sec 1 datagrams received out-of-order
Es decir, y resumiendo lo que exponíamos al principio, da igual que dejemos la prueba haciéndose durante un buen rato, pongamos 1200 segundos, para que nuestro querido Munin grafique algo:
# iperf -t 1200 -c 10.92.92.2 ------------------------------------------------------------ Client connecting to 10.92.92.2, TCP port 5001 TCP window size: 85.0 KByte (default) ------------------------------------------------------------ [ 3] local 10.92.92.1 port 43672 connected with 10.92.92.2 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-1200.0 sec 13.2 GBytes 94.2 Mbits/sec
Bandwith bond0:
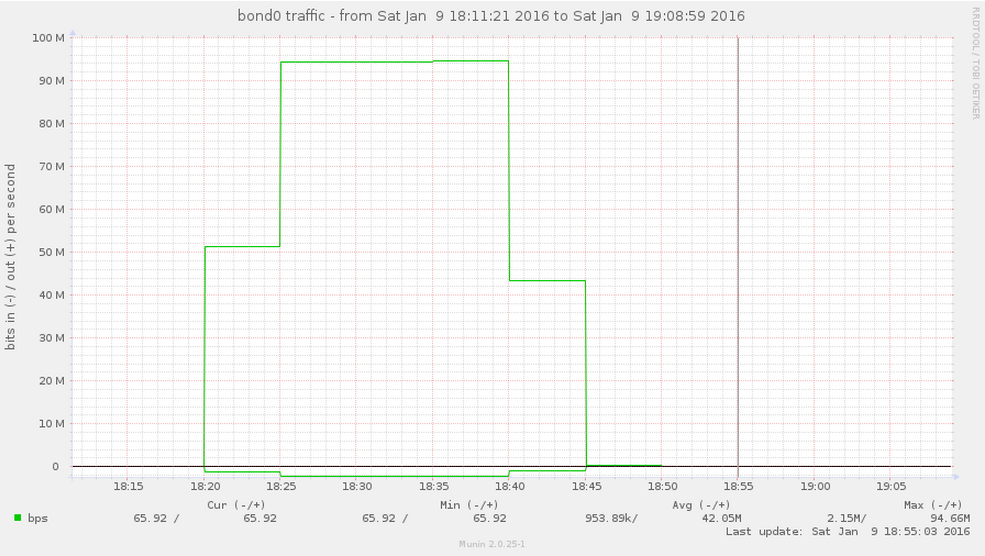
y en paralelo, las dos underlying nic’s (eth3/eth4) presentan:
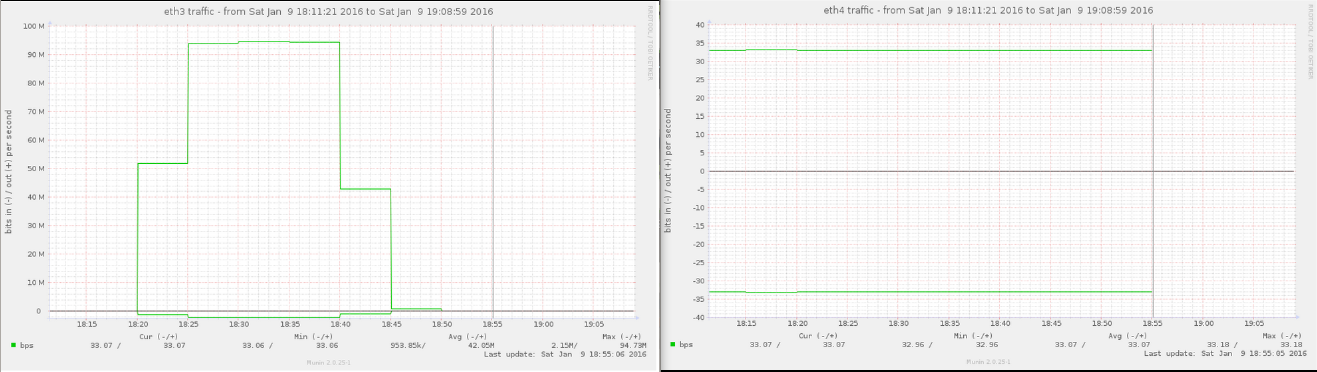
es decir, 0 uso en eth4 (escasos bps de los TLV’s).
Con ello, lo que comentábamos de los Elephant Flows ha quedado ilustrado 🙂
Con la gorra de warriors of the net: multipath TCP – first approach
De cara a continuar con el post, las bases de multipath TCP se explican en este vídeo (Google Tech Talks), Costin Raiciu (University Politehnica of Bucharest), merece la pena francamente:
Instalando el kernel Multipath TCP
Las sources lists para Debian 8 64bits standard serían las oficiales:
deb http://multipath-tcp.org/repos/apt/debian jessie main
y el meta-paquete se llama: linux-mptcp
Lo que se nos instala principalmente es el kernel, las net-tools / iproute2 con soporte multipath tcp las tenemos que compilar a mano.
Configurando un par de tablas de routing
De cara a nuestra laboratorio de pruebas multipath TCP, sentemos esta base de direccionamientos asignados, desmontando por tanto todo el bond0 comentado:
- host 01
- eth3 10.93.93.1/30
- eth4 10.94.94.1/30
- host02
- eth3 10.93.93.2/30
- eth4 10.94.94.2/30
Damos de alta las dos tablas en /etc/iproute2/rt_tables
# reserved values # 255 local 254 main 253 default 0 unspec # local 3 niceth3 4 niceth4
Y generamos las reglas para que cuando, como origen, sean dichas NIC’s, se analice la tabla vinculada concreta que acabamos de definir.
ip rule add from 10.93.93.0/30 table niceth2 ip route add 10.94.94.2/32 via 10.93.93.2 table nic eth2 ip rule add from 10.94.94.0/30 table niceth3 ip route add 10.93.93.2/32 via 10.94.94.2 table niceth3
(lo deberíamos dejar en boot-time – post-up de /etc/network/interfaces)
Con estas reglas, lo que hacemos es instruir al kernel: «Oye, si sacas un paquete con ese origen, que sepas que la tabla de routing a mirar es XXX».
Y es importante definirlo, para que cuando MultipathTCP intente establecer los subflows con las diferentes NIC’s tenga éxito.
Primera prueba con Multipath TCP
Nada más bootear nuestros servers con el kernel específico con soporte, basta con hacer un iperf entre supuestamente únicamente 2 NIC’s (deberíamos obtener 100Mbs y fin):
root@mpath01:~# iperf -c 10.93.93.2 ------------------------------------------------------------ Client connecting to 10.93.93.2, TCP port 5001 TCP window size: 85.0 KByte (default) ------------------------------------------------------------ [ 3] local 10.93.93.1 port 42062 connected with 10.93.93.2 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 333 MBytes 279 Mbits/sec
De hecho, basta con dejar abierto un IPTRAF o BMON e ir viendo como se ponen los tres interfaces a full.
De cara a verlo mas gráficamente, si dejamos el iperf durante un buen rato, las gráficas de las NIC’s:

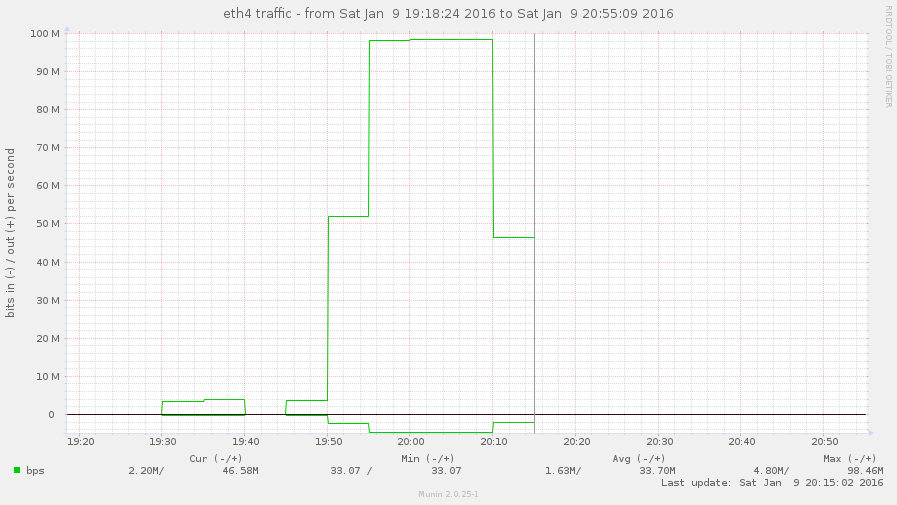
Perooo… ¿por qué y cómo se ha activado by default? WTF? ¿Cómo veo los subflows? [!]
Lo primero de todo es tener en cuenta que multipath tcp se ha diseñado para que las aplicaciones no tengan ningún cambio en sus llamadas a las funciones de creación y gestión de sockets stream (tcp), así que es todo totalmente automático: desde IPERF hasta cualquier aplicación standard de usuario (Navegador Web, SIP TCP, …).
De cara a ver lo que está pasando con nuestros sockets, lo primero de todo es instalar las MULTIPATH TCP related tools:
- https://github.com/multipath-tcp/net-tools
- Para poder tener netstat y resto de comandos con información de multipath.
- https://github.com/multipath-tcp/iproute-mptcp
- Para poder tener el comando «ip» con soporte, ip link multipath y derivados nos vienen muy bien.
Así que tras lanzar la prueba, hacemos uso del nuevo comando netstat, al que se le añade la opción ‘m’ (de multipath):
Proto Recv-Q Send-Q Local Address Foreign Address State Local Token Remote Token User Inode tcp 0 78540 10.93.93.1:60312 10.94.94.2:5001 ESTABLISHED root 15240 tcp 0 55692 10.93.93.1:40770 10.10.0.114:5001 ESTABLISHED root 15240 tcp 0 84252 10.10.0.121:44461 10.10.0.114:5001 ESTABLISHED root 15240 tcp 0 58548 10.10.0.121:38856 10.94.94.2:5001 ESTABLISHED root 15240 tcp 0 72828 10.94.94.1:53674 10.93.93.2:5001 ESTABLISHED root 15240 tcp 0 62832 10.94.94.1:57469 10.94.94.2:5001 ESTABLISHED root 15240 tcp 0 67116 10.10.0.121:40012 10.93.93.2:5001 ESTABLISHED root 15240 tcp 0 67116 10.93.93.1:42267 10.93.93.2:5001 ESTABLISHED root 15240 tcp 0 62832 10.94.94.1:52238 10.10.0.114:5001 ESTABLISHED root 15240 mptcp 0 1122408 10.93.93.1:42267 10.93.93.2:5001 ESTABLISHED 2805464892 3190065287 root 15240
Como se puede observar, de forma activa, el kernel con soporte MPTCP, cuando desde espacio de usuario (iperf) se ha solicitado conectarse a 10.93.93.2:
- Le ha asignado el puerto cliente random 42267 e ip origen 10.93.93.2 (dado que a nivel de routing ese el src a sacar)
- Ha lanzado todo el resto de posibles subflows existentes entre los hosts: FULL MESH!
Una vez que tenemos instaladas las net-tools e iproute2 con soporte Multipath, basta con ejecutar un ip link help para que nos saque las opciones:
ip link set { DEVICE | dev DEVICE | group DEVGROUP } [ { up | down } ]
[ arp { on | off } ]
[ dynamic { on | off } ]
[ multicast { on | off } ]
[ allmulticast { on | off } ]
[ multipath { on | off | backup } ]
De hecho, si desactivamos multipath en las 3 nics y de nuevo lanzamos la prueba de IPERF, obtenemos los 100Mbits esperados:
root@mpath01:~# ip link set eth0 multipath off root@mpath01:~# ip link set eth3 multipath off root@mpath01:~# ip link set eth4 multipath off root@mpath01:~# iperf -c 10.93.93.2 ------------------------------------------------------------ Client connecting to 10.93.93.2, TCP port 5001 TCP window size: 85.0 KByte (default) ------------------------------------------------------------ [ 3] local 10.93.93.1 port 42575 connected with 10.93.93.2 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 111 MBytes 93.0 Mbits/sec
Fight! Objetivo: Full IP over the multipath tcp
Llegados a este punto, tenemos un kernel que permite, entre dos máquinas, aprovechar todos los paths disponibles para que las conexiones entre ellos vayan más rápidos / sean tolerantes a cortes de un path.
Pero: ¿Y si queremos no sólo tcp, sino tb UDP o cualquier protocolo IP? ¿Y si queremos estirar la posibilidad para que sea todo el tráfico incluso el que no vaya destino al servidor? (está claro que tiene que psar por él).
Las propuestas, que aparecen (Obviando lo descabellado que es tunelizar IP over TCP) serían:
- Full SSH Túnel (no sólo port forwarding).
- OpenVPN Over TCP.
- (y otras posibles alternativas de túneling IP over TCP).
Round 1: SSH Tunneling
En ambos casos se obtiene un interface tun/tap por el cual rutar el tráfico, así que obtaremos por SSH por la facilidad de despliegue, con zero configuración necesaria. Sirva el siguiente esquema para ilustrar lo que estamos levantando:
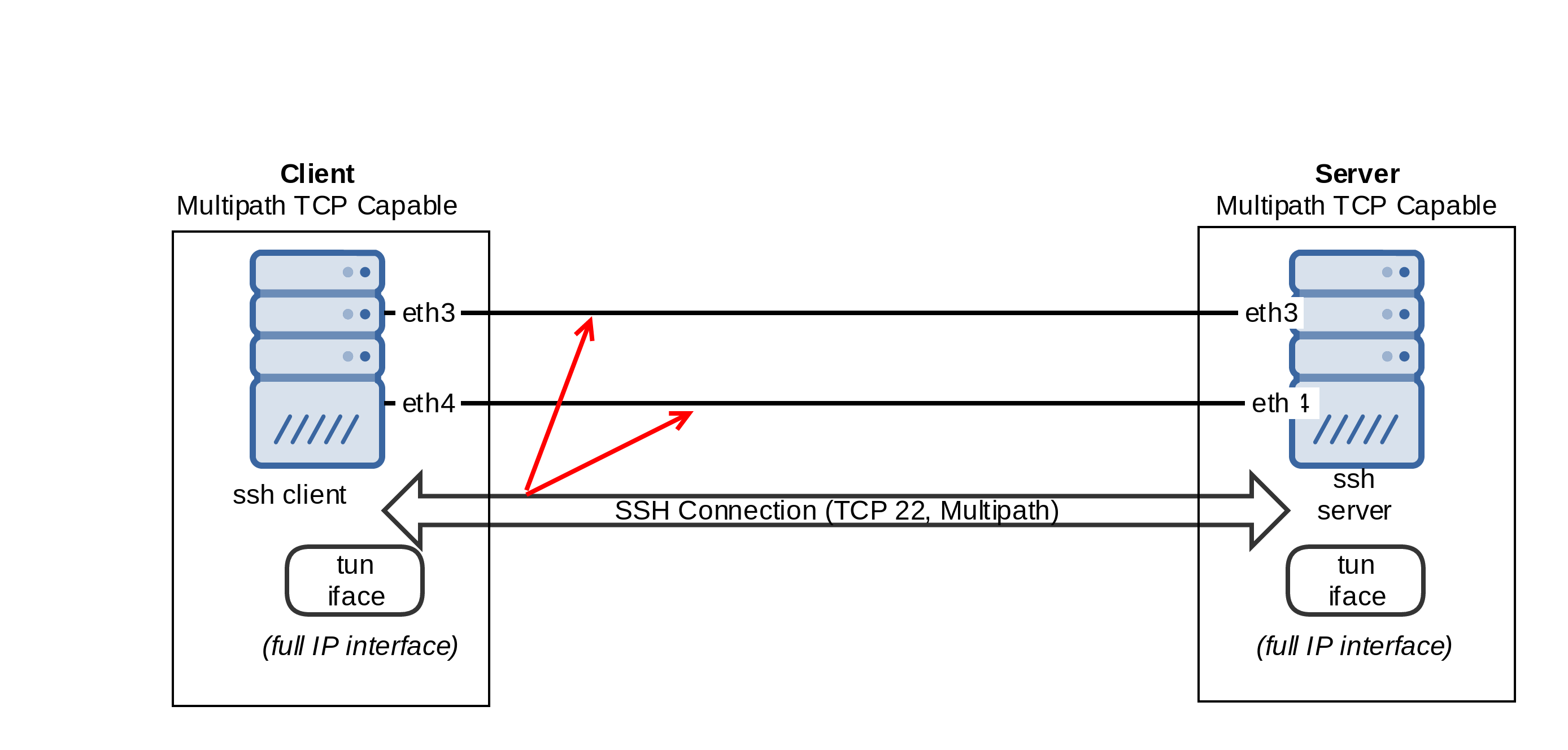
Para soportar ifaces tipo VPN over SSH, en sshd_config es necesario:
PermitTunnel Yes
Una vez permitido, basta con ejecutar en el cliente:
ssh -w 0:0 [email protected]
Una vez ejecutado el comando, podemos configurar en cada host el túnel:
cliente
ifconfig tun0 10.91.91.1 pointopoint 10.91.91.2
servidor
ifconfig tun0 10.91.91.2 pointopoint 10.91.91.1
Lo que tenemos, por tanto, es una unión full IP, que por debajo se basa en SSH, que a su vez se basa en TCP y por tanto, multipath capable! Yessss!
La primera prueba nos arroja unos resultados realmente desastrosos, del orden de escasos MBit’s:
Analizando el load / cpu, se concluye rápidamente que lo que está sucediendo es que estamos siendo limitados por CPU Power, no por nada que tenga que ver con Networking, objeto de esta entrada 😉 Así que para facilitarle las cosas a SSH, desactivamos la compression (que por defecto es DELAYED y genera ese efecto):
Compression no
Sin embargo, los resultados no son del todo correctos tampoco, asumimos que es por la existencia de cifrado en bloques y similares, con SSH no es fácil (sin recompilar) desactivar en una Debian default.
Round 2: Openvpn tunneling (no cipher)
En esta ocasión, optamos por definirnos un túnel OpenVPN totalmente mínimo, sin autenticación ni cifrado ni nada, para pruebas.
En un lo de los equipos, el que actúa como servidor:
persist-tun proto tcp-server dev ptp dev-type tun port 1200 ifconfig 10.96.96.2 10.96.96.1 keepalive 10 120 cipher none auth none
El que tiene rol como cliente:
persist-tun proto tcp-client dev ptp dev-type tun port 1200 ifconfig 10.96.96.1 10.96.96.2 remote 10.93.93.2 keepalive 10 120 cipher none auth none
Puntos a comentar sobre esta configuración:
- Es totalmente insegura (obvio), mejor que no salga de una jaula de faraday, o ni tan siquiera eso 😉
- Es importante no definir «local» en el cliente, para no forzar un socket origen
Tras lanzar esta prueba, los resultados tampoco son del todo positivos.
Pero lo que podemos observar, tras compilar las net-tools respectivas con soporte multipath tcp:
Conexiones TCP
root@test1:~# netstat -tnp | grep 1200 | grep ESTA tcp 0 0 10.96.96.1:50438 10.94.94.2:1200 ESTABLISHED 3421/openvpn tcp 0 0 10.93.93.1:54299 10.94.94.2:1200 ESTABLISHED 3421/openvpn tcp 0 0 10.94.94.1:51703 10.93.93.2:1200 ESTABLISHED 3421/openvpn tcp 0 0 10.93.93.1:50189 10.93.93.2:1200 ESTABLISHED 3421/openvpn tcp 0 0 10.94.94.1:57796 10.94.94.2:1200 ESTABLISHED 3421/openvpn tcp 0 0 10.93.93.1:36725 10.96.96.2:1200 ESTABLISHED 3421/openvpn tcp 0 0 10.94.94.1:44662 10.96.96.2:1200 ESTABLISHED 3421/openvpn tcp 0 0 10.96.96.1:43723 10.93.93.2:1200 ESTABLISHED 3421/openvpn tcp 0 0 10.96.96.1:49206 10.96.96.2:1200 ESTABLISHED 3421/openvpn
Conexiones Multipath
root@test1:~# netstat -m Active Internet connections (w/o servers) Proto Recv-Q Send-Q Local Address Foreign Address State Local Token Remote Token mptcp 0 0 10.93.93.1:50190 10.93.93.2:1200 ESTABLISHED 2191762672 1766982750
¿Qué es lo que está pasando en concreto?
¡Se está auto-realimentando! Es decir, están saliendo conexiones tcp multipath para establecer el túnel, ¡por el propio túnel!
Round 3: Win!
Teniendo compiladas las net-tools, podemos ejecutar «ip link set multipath off dev tun..», pero el caso es que se levanta en runtime, con lo que la setting va y viene y no está ready.
Así que optamos por el carril del medio y directamente en el equipo que lanza el túnel:
iptables -I OUTPUT -s 10.96.96.1 -p tcp --dport 1200 -j REJECT
Seguramente haya una forma mucho mas elegante (persist-tun y tunctl de uml-utilities ?), pero estamos hablando de pruebas de concepto así que vamos en automático !
Con ello, las conexiones TCP y TCP Multipath nos quedan ya limpias:
root@test1:~# netstat -m Active Internet connections (w/o servers) Proto Recv-Q Send-Q Local Address Foreign Address State Local Token Remote Token mptcp 0 0 10.93.93.1:50190 10.93.93.2:1200 ESTABLISHED 2191762672 1766982750 root@test1:~# netstat -tnp | grep 1200 tcp 0 0 10.93.93.1:47859 10.94.94.2:1200 ESTABLISHED 3508/openvpn tcp 0 0 10.94.94.1:55379 10.96.96.2:1200 ESTABLISHED 3508/openvpn tcp 0 0 10.94.94.1:38949 10.93.93.2:1200 ESTABLISHED 3508/openvpn tcp 0 0 10.94.94.1:45733 10.94.94.2:1200 ESTABLISHED 3508/openvpn tcp 0 0 10.93.93.1:43482 10.96.96.2:1200 ESTABLISHED 3508/openvpn tcp 0 0 10.93.93.1:50190 10.93.93.2:1200 ESTABLISHED 3508/openvpn
Y, ¡finalmente!, los resultados son positivos, en el equipo2, que únicamente tiene 2 nic’s a 100Mbs:
eth0: negotiated 100baseTx-FD, link ok eth1: negotiated 100baseTx-FD, link ok
Conseguimos superar la barrera de los 100Mbs en tráfico UDP! :
iperf -c 10.10.0.201 -u -b 300M ------------------------------------------------------------ Client connecting to 10.10.0.201, UDP port 5001 Sending 1470 byte datagrams UDP buffer size: 160 KByte (default) ------------------------------------------------------------ [ 3] local 10.96.96.2 port 39703 connected with 10.10.0.201 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 359 MBytes 302 Mbits/sec [ 3] Sent 256410 datagrams [ 3] Server Report: [ 3] 0.0-10.2 sec 191 MBytes 156 Mbits/sec 15.108 ms 120226/256407 (47%)
Es decir, estamos obteniendo 156Mbits, que entre el overhead de openvpn, overhead de tcp, los ACK’s y tal, ¡nos parece más que digno!
Resumiendo, el escenario logrado es:
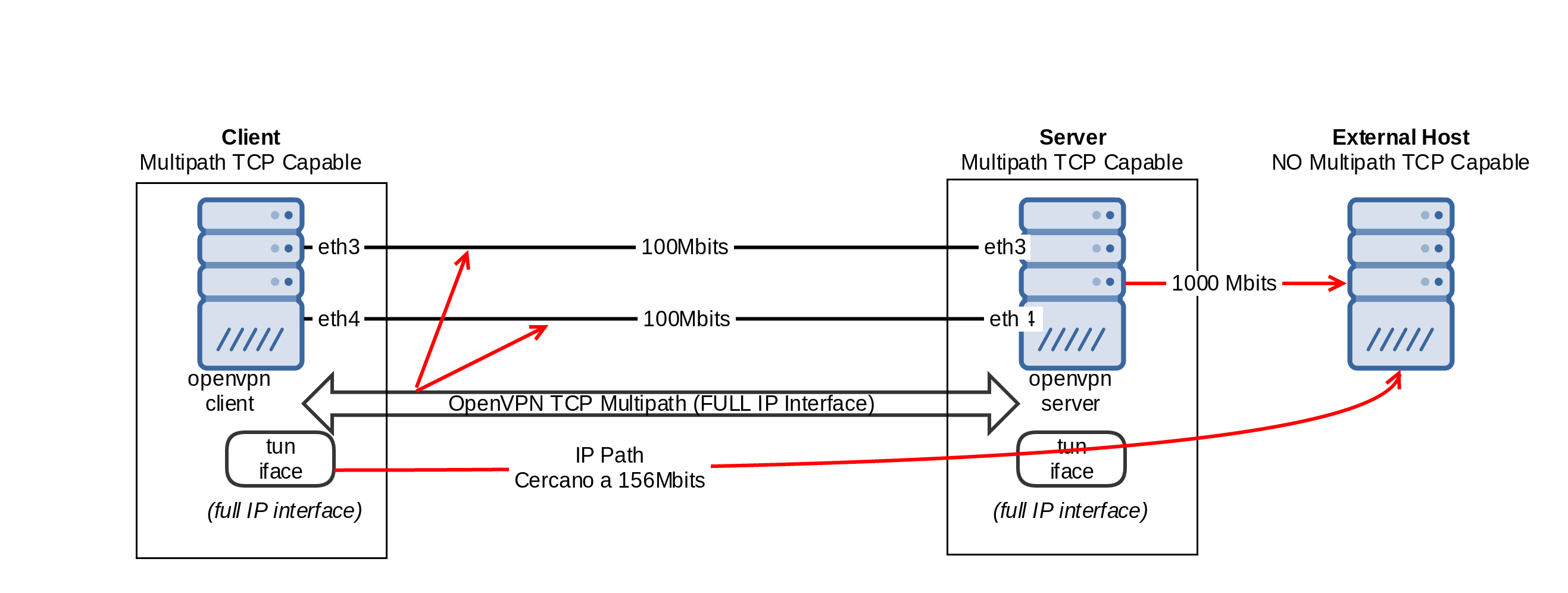
Despedida y algunas consideraciones
Esto se trata únicamente de pruebas de laboratorio. Hay que poner especial atención al hecho de que tunelizar IP over TCP no es una idea del todo correcta, ni tampoco es la solución a nada de HA final, dónde las soluciones de routing dinámico cumplen con creces sus cometidos y trabajan en la capa IP.
Esta prueba de concepto es, simple y llanamente, por amor al arte / lab / Networking Warriors 😉
Sin embargo, las aplicaciones en sí de multipath tcp de base son increíbles, sobre todo para los temas de roaming 3G/Wifi y similares. De hecho, incluso Apple lo especifica en detalle. Para Android, todavía parece que no es oficial y hay que hacer un deploy de un custom kernel.
Sea como fuere, es un campo interesante. En cuanto tengamos algo de tiempo plantearemos algún escenario, seguramente con SIP TCP | TLS con Multipath TCP, para hacer algunas pruebas de concepto.
Como anécdota final, comentar que hace muuuuucho tiempo, cuando montamos El Reto Vodafone, teníamos como objetivo lograr mas throughput a través de una batería de enlaces 3G, obviando todos los temas de celdas y densidad. Gracias al súper Ninja Network Warrior original, un humilde aspirante y él montamos juntos un bonding agregando VPN’s y, claro, no conseguíamos multiplicar el throughput disponible para el flow que hacía el streaming (Con Red5 RTMP por aquella época, si no recordamos mal 🙂 Quién sabe… hace 9 años ya de ello. Quizás con este camino hubiéramos conseguido que el Elephant Flow cupiese en el embudo 😉
1 Comentario
¿Por qué no comentas tú también?
Buenas, sabéis cómo se podría probar live streaming y video on demand por encima de mptcp? con qué programa puede funcionar?
Gracias.
delia Hace 10 años
Queremos tu opinión :)