Hoy os traemos un nuevo post en el que os contamos cómo hemos realizado el escalado de un sistema que se encontraba en un único servidor a un sistema completo en alta disponibilidad y separado por capas, en la que cada capa se encarga de realizar una única tarea, al más puro estilo KISS (keep it simple, stupid!).
Podríamos mencionar también al principio «si algo funciona, no lo toques»™, pero en informática eso no suele ser lo habitual. Normalmente, tenemos que adelantarnos a los acontecimientos y prepararnos para que lo que hasta ahora podía funcionar en un único servidor en breve no pueda. Ello nos lleva a pensar en el escalado horizontal.
Este es el caso que os traemos hoy: un servidor que hasta ahora era capaz de servir la carga que recibía, pero el que se espera que vaya a recibir bastante impacto y que no puede pararse en el momento en el que llegue. El servidor cuenta con Nginx como servidor web, MySQL como base de datos y código en PHP, algo bastante habitual en nuestros desarrollos.
El análisis
Dadas las nuevas necesidades que se nos plantean, decidimos realizar un análisis para ver si aparte de la arquitectura de servicio debemos realizar alguna otra modificación que sea necesaria para abordar el proyecto. Teniendo en cuenta el cambio que se va a realizar, se aprovecha para actualizar el proyecto, y ciertos warnings que aparecen por el cambio a la última versión de PHP, se pulen y arreglan.
En este aspecto, y en lo que se refiere al departamento de desarrollo, destacar que no surgen problemas ya que se trata de un proyecto que se ha ido evolucionando a lo largo del tiempo. Es decir, podemos decir que no es algo «arcaico» y que se haya quedado congelado en el tiempo. De todas maneras y gracias a Docker, tampoco hubiese habido problemas en poder hacer funcionar un proyecto con una versión antigua de PHP, pero afortunadamente, no era el caso.
La nueva arquitectura
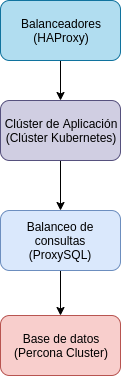
Como hemos comentado, se va a pasar de un único servidor a una plataforma completamente nueva en Alta Disponibilidad. Bien es cierto podríamos habernos ido a un sistema de tres servidores, en el que cada uno de ellos cuente con todos los servicios que vamos a necesitar. Sin embargo, decidimos usar nuestro stack de servicios que ya tenemos más que probado.
HAProxy (balanceadores HTTP)
HAProxy es un balanceador HTTP/HTTPS (aunque también puede usarse en modo TCP) del que estamos enamorados. Es una solución que nos permite recibir miles de peticiones y hacer lo que queramos con ellas. Sólo HAProxy da para un post entero, pero vamos a centrarnos en los aspectos más destacados que vamos a usar en este caso:
- Balanceo de carga: Es su principal función, pero no la única. Como buen proxy, recibe las peticiones y podemos balancearlas sobre los backends que le indiquemos de la manera en la que mejor nos convenga (balanceo round-robin, por pesos, el que menos peticiones tenga…). Lo mejor es que es capaz de saber el estado de los backend, y si uno de ellos no se encuentra para recibir peticiones, lo saca del pool y no le manda más peticiones hasta que no vuelva a un estado correcto.
- Redireccionador: Tenemos varios tipos de redirecciones creadas, no sólo la típica de pasar de HTTP a HTTPS, si no cambios en la URL e incluso peticiones que deben de ser modificadas al vuelo.
- SSL-Offloading: Configuramos en el haproxy los certificados SSL y hacemos que él se encargue de realizar el cifrado, quitando carga a los servidores backend.
Cada semana aprendemos cosas nuevas de HAProxy, y la verdad es que merece la pena cada minuto que le dedicamos.
Clúster Kubernetes (aplicación en Docker)
![]() Hemos aprovechado a pasar la aplicación a una imagen Docker que tenemos alojada en nuestro registry GitLab. Gracias a todo el bagaje que tenemos ya desarrollando con Docker, lo hemos aplicado para crear una imagen que hace que la aplicación pueda ser desplegada en segundos en cualquier entorno Docker o, en el caso de producción, en un clúster Kubernetes que tenemos.
Hemos aprovechado a pasar la aplicación a una imagen Docker que tenemos alojada en nuestro registry GitLab. Gracias a todo el bagaje que tenemos ya desarrollando con Docker, lo hemos aplicado para crear una imagen que hace que la aplicación pueda ser desplegada en segundos en cualquier entorno Docker o, en el caso de producción, en un clúster Kubernetes que tenemos.
Gracias a nuestro departamento de desarrollo, la imagen creada cuenta con todo el código PHP y librerías que son necesarias para la correcta puesta en marcha de la aplicación, por lo que levantar una instancia o N de la misma en el clúster Kubernetes es cuestión de un segundo.
De esta manera, el escalado horizontal de la aplicación lo podemos realizar de manera sencilla en todos los nodos del clúster Kubernetes que tenemos.
Lógicamente, esta imagen también es utilizada para el desarrollo. Por lo tanto, de igual manera, el poder tener una instancia en la que desarrollar en local es cuestión de unos pocos segundos: loguearnos en el registry, pedir la imagen y levantar un contenedor. Fácil, sencillo y para toda la familia 😀
ProxySQL como balanceador de consultas 
Delante de la base de datos tenemos un sistema en clúster (recordad la importancia de la Alta Disponibilidad) con el servicio ProxySQL. Este proyecto, que ahora a la gente de Percona le está gustando mucho y lo incluye en sus repositorios, actúa de proxy, pudiendo realizar no sólo balanceo de consultas, si no también de caché.
Entre las ventajas con las que cuenta, es que también detecta el estado de los backends de MySQL (o en nuestro caso, como veréis a continuación, los Percona XtraDB Cluster). Por tanto, es el propio ProxySQL el que sabe si va a poder mandar una consulta a un nodo o no.
Ya hemos estado jugando con las opciones de caché, y hay que admitir que aunque la necesidad de usar una caché tipo Redis (donde poder almacenar HTML ya generado previamente y/o sesiones) siga siendo necesaria, nos puede permitir quitar carga de caché a los nodos backend.
Por último, una característica que todavía no hemos puesto en producción, pero con la que hemos hecho pruebas, es la de realizar reescrituras de peticiones. Es cierto que no es una característica que necesitemos de manera habitual (como si nos pasa con el HAProxy), pero está bien saber que podemos contar con ella.
Percona XtraDB Cluster
 Por último, y por supuesto no lo menos importante, es el sistema de base de datos elegido. Tal como hemos comentado, el proyecto inicialmente contaba con un único servidor, por lo que la base de datos estaba en él. Es cierto que teníamos un esclavo de MySQL que utilizábamos para realizar los backups (y así quitar carga al servidor principal), pero no era utilizado para nada más.
Por último, y por supuesto no lo menos importante, es el sistema de base de datos elegido. Tal como hemos comentado, el proyecto inicialmente contaba con un único servidor, por lo que la base de datos estaba en él. Es cierto que teníamos un esclavo de MySQL que utilizábamos para realizar los backups (y así quitar carga al servidor principal), pero no era utilizado para nada más.
A la hora de realizar el análisis se barajó el hacer uso de un sistema Maestro ⬌ Maestro en MySQL. Finalmente, nos terminamos decantando por un sistema de 3 nodos Percona XtraDB Cluster. A la hora de elegir un sistema con Percona XtraDB Cluster tendremos que asegurarnos que no usamos características que no sean compatibles (tablas temporales, por ejemplo), pero en principio no debería suponer ningún problema.
Y ya que estamos con Percona, por si no lo conocéis, no os olvidéis echar un ojo a las Percona Toolkit y al sistema de backups que tienen, ya que son muy útiles y siempre viene bien conocer herramientas nuevas.
Resumen
En este post no os hemos detallado técnicamente cómo montar la solución de todo el stack de servicios de la plataforma, pero os hemos dado una introducción a una posible solución, o lo que en inglés se denomina, una big picture del proyecto. En próximos posts, intentaremos adentrarnos a nivel técnico de cada una de las capas.
Y como siempre, si necesitáis una infraestructura de sistemas como esta o un análisis de vuestras necesidades, no dudéis en poneros en contacto con nosotros para que podamos colaborar en vuestro proyecto.
1 Comentario
¿Por qué no comentas tú también?
[…] La primera pregunta pregunta hace referencia a nuestros datos corporativos como ERP, CRM, gestión documental, herramientas de gestión de proyectos, repositorio de ficheros compartidos, etc. Lo más importante es tener los datos en una infraestructura que cuente con mecanismos para garantizar la alta disponibilidad, accesibilidad garantizada y la persistencia de los datos ante un desastre mediante un buen sistema de backup. Ya hablábamos en más profundidad del paso de entornos clásicos monoserver a entornos de alta disponibilidad este post de nuestro blog. […]
COVID19 en el sector tecnológico: teletrabajo frente a la crisis - Blog Irontec Hace 6 años
Queremos tu opinión :)