
Herman Hollerith observa orgulloso el tabulador mecánico capaz de contabilizar los resultados de las tarjetas perforadas
En las últimas décadas los sistemas de información han ido adquiriendo una importancia cada vez más relevante en el día a día, siendo imposible imaginar las sociedades actuales sin su existencia y habiéndose convertido en el activo más importante de las empresas.
Desde que Herman Hollerith (1860 – 1929) desarrollara la tecnología para el procesamiento de las tarjetas perforadas con motivo del censo de los Estados Unidos de América en 1890 (algo que posteriormente daría lugar a IBM, pero eso es una historia que merece ser contada aparte) hasta los modernos Centros de Proceso de Datos (ej: Utah Data Center) nuestros datos, tanto públicos como privados, han recorrido un largo camino.
Desde el inicio de esta «larga marcha» tanto ingenieros y diseñadores como usuarios enfrentaron la misma problemática: ¿cómo evitar que la información se corrompa o, peor aún, se pierda irremediablemente? Por por si esto no fuese suficiente conforme la información iba creciendo y se tornaba imprescindible apareció una nueva necesidad: inmensos volúmenes de datos debían estar disponibles para multitud de personas simultáneamente.
La respuesta a estas cuestiones nunca ha sido sencilla; la heterogeneidad de los sistemas de almacenamiento de información, unido a los condicionantes inherentes a las actividades humanas (terrorismo, cambios socio-políticos) y naturales (catástrofes de la más diversa índole) hacen del mantenimiento y acceso a grandes volúmenes de información una tarea sumamente compleja.
A lo largo de una serie de artículos vamos a intentar dar pequeñas respuestas a pequeñas preguntas, presentando las soluciones parciales que se han ido implementando con el fin de asegurar, al menos a ciertos niveles, que la información de la que dependen nuestros sistemas en su día a día esté disponible. En este primer artículo hablaremos de los niveles de RAID (Array Redundante de Disco Independientes).
«Data is a precious thing and will last longer than the systems themselves.» Tim Berners-Lee
Un RAID (acrónimo inglés de Redundant Array of Independent Disks, aunque inicialmente era Redundant Array of Inexpensive Disks) es un sistema de almacenamiento de datos que usa múltiples unidades de almacenamiento (discos) para presentarlos como una única unidad lógica. Dicho de otro modo: dos o más discos agrupados de manera que se presentan como un único dispositivo de almacenamiento al sistema anfitrión.
Un poco de historia
Durante la segunda mitad del siglo XX (ya que no existían hasta 1956) el precio por MB de los discos duros (soportes magnéticos de almacenamiento) fue reduciéndose a la par que su capacidad de almacenamiento crecía y su velocidad se incrementaba. Esto los convirtió, a partir de mediados de los 80, en el principal subsistema de almacenamiento de los sistemas informáticos, siendo de este modo el soporte responsable del almacenamiento persistente más importante, motivo por el cual su fiabilidad, disponibilidad y rendimiento pasó a ser una cuestión prioritaria.

RAID1 (1989) – Sun 4/280 WS, 128MB DRAM, 4 controladoras SCSI, 28HD SCSI 5.25» (discos en espejo por software)
Corría en año 1987 cuando un grupo de científicos computacionales (sí, se dice así) de la «University of California at Berkeley» (David Patterson, Garth A. Gibson, y Randy Katz) definieron por primera vez la tecnología RAID, dándola a conocer en la publicación «A Case for Redundant Arrays of Inexpensive Disks (RAID)«, estudiando la posibilidad de que dos o más discos apareciesen como un único dispositivo ante el sistema anfitrión. La etimología del acrónimo se refería en un primer momento a discos «asequibles» (inexpensive) en relación al uso de discos destinados al creciente mercado de consumo en contraposición a los caros discos de alto rendimiento de los mainframes de la época.
La finalidad del estudio de los científicos era proporcionar una arquitectura redundante que ofreciese cierta tolerancia ante fallos de los discos, a partir de lo cual definieron los niveles RAID 1 y 5. También estudiaron el striping de discos como una manera de incrementar el índice de transmisión del sistema (throughput) aunque en este caso no existiese redundancia en la configuración; comúnmente se conoce esta configuración como RAID 0.
Puntos clave de la adopción de la tecnología RAID
Indudablemente la tecnología RAID presenta una serie de ventajas, como es la posibilidad de utilizar discos relativamente asequibles para crear un sistema de almacenamiento de alta capacidad y/o rendimiento tolerante a fallos. Por tanto, los puntos claves para la adopción de esta tecnología pueden considerarse los siguientes:
- Capacidad: Creación de grandes volúmenes de almacenamiento para la distribución de información en base a pequeños discos independientes.
- Rendimiento: Incremento del rendimiento en las operaciones de acceso a los volúmenes de información, permitiendo una mayor concurrencia.
- Disponibilidad: Tolerancia a fallos (dependiente del nivel de RAID), reduciendo la posibilidad de que la información quede inaccesible, justificando así el sobrecoste derivado de la redundancia requerida, sobre todo en grandes volúmenes con gran concurrencia de accesos.
La relación que queramos lograr entre estos factores: capacidad <=> rendimiento <=> disponibilidad, unido al sobrecoste que estemos dispuestos a asumir por el incremento de la capacidad de almacenamiento (veremos que coste y capacidad van de la mano en función de la tolerancia a fallos) definirán el nivel RAID a implementar para un determinado sistema.
Niveles RAID
Existen multitud de niveles RAID o «esquemas de redundancia», cada uno de ellos con una relación coste/capacidad <=> rendimiento <=> disponibilidad diferente destinados a satisfacer diferentes necesidades, ya que no puede hablarse de que un nivel sea inherentemente superior a otro.
En un determinado nivel RAID la disponibilidad (recordemos que estamos hablando de tolerancia a fallos) se logra mediante la redundancia, la cual puede venir dada gracias a la información de paridad o por duplicidad de la información. Estos conceptos pueden resumirse de la siguiente manera:
- Paridad: sistema para la detección de errores que proporciona tolerancia a errores para un conjunto de datos en base a diversas operaciones. Consultar más información sobre el cálculo de la paridad.
- Duplicidad: como su propio nombre indica consiste en replicar un conjunto de información en una unidad de almacenamiento físicamente independiente.
Como medida adicional, en diversos niveles RAID existe la posibilidad de indicar discos de repuesto (spare), consistentes en unidades de almacenamiento que se mantienen en un estado de reserva a expensas de que tenga lugar un fallo en alguno de los discos para ocupar su lugar. En este caso el disco de repuesto debe reconstruirse mediante el uso de la información de paridad o duplicidad existente, y el RAID (dependiendo del nivel) se encontrará en un estado inconsistente/inseguro hasta que este proceso finalice.
RAID 0
Este nivel RAID nos permite distribuir los datos equitativamente entre dos o más discos (stripping) sin que se lleve a cabo ningún tipo de duplicidad ni cálculo de paridad sobre la información almacenada.
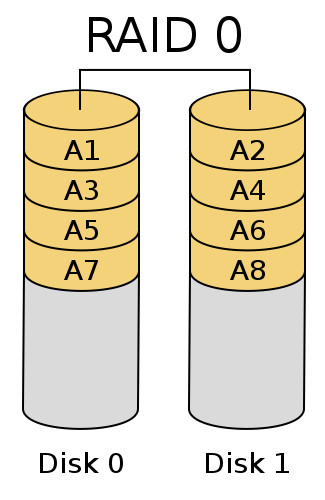
RAID 0
- Características generales:
- Un determinado dato se distribuye entre todos los discos que forman parte del RAID en una unidad de distribución denominada chunk que determina el tamaño en que se segmentará. De este modo, tanto en operaciones de lectura como de escritura se accede a numerosos discos simultáneamente, obteniendo en condiciones óptimas un rendimiento teórico máximo equivalente al de la suma de los discos a nivel individual.
- Este nivel de RAID es inherentemente inseguro para la información almacenada, pero puede utilizarse en entornos donde el rendimiento es prioritario frente a la integridad de los datos.
- La configuración del RAID 0 puede realizarse sobre discos de diferentes tamaños, pero se tomará como referencia el menor de ellos (a nivel de sector) y sólo se utilizará esa capacidad de los discos restantes, quedando el resto inutilizable.
- Ventajas: si se tiene en cuenta el tamaño de los discos (según lo indicado anteriormente) no se pierde espacio de almacenamiento y en términos generales el rendimiento será superior al de las unidades de almacenamiento a nivel individual.
- Desventajas: en algunas circunstancias, según al configuración del chunk y el tipo de dato a almacenar estaremos desperdiciando gran cantidad de espacio de almancenamiento y, lo más importante, el fallo de un disco hará que perdamos toda la información.
RAID 1
Este nivel RAID delega la integridad de la información en la duplicidad de la misma en un conjunto de dos o más discos. Es decir, la información almacenada en un único disco se replica íntegramente al menos en otro disco.
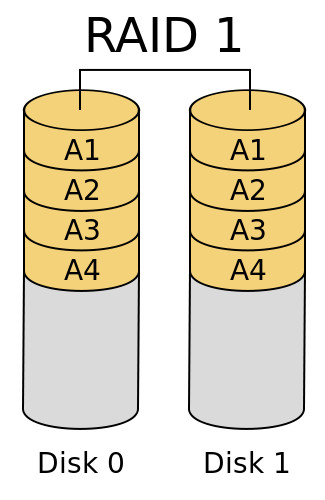
RAID 1
- Características generales:
- Un determinado dato se almacena en un único disco y es replicado al menos en otro disco.
- Este nivel de RAID se utiliza cuando la integridad de la información es más importante que el rendimiento o la capacidad de almacenamiento.
- La máxima capacidad de almacenamiento de un RAID 1 viene dada por el más pequeño de sus miembros individuales, y aunque podamos utilizar discos de distintos tamaños sólo podremos aprovechar hasta dicho tamaño en discos de mayor tamaño, quedando el resto inutilizable.
- El rendimiento de lectura en un RAID 1 puede llegar a ser el equivalente a la suma del rendimiento de los miembros que lo forman, mientras que el rendimiento de escritura será el equivalente al más lento de los discos (o incluso inferior en determinadas circunstancias).
- Ventajas: se considera un nivel RAID muy seguro para el almacenamiento de la información, ya que para perder información deberían estropearse todos los discos que forman parte de él; mientras haya un disco en funcionamiento podrá reconstruirse el RAID.
- Deventajas: este nivel de RAID desperdicia gran cantidad de espacio de almacenamiento en pos de su integridad (el porcentaje de espacio utilizable se corresponde en el mejor de los casos con 100/[nº de discos]).
RAID 2
Este nivel RAID distribuye los datos a nivel de bit y utiliza un código Hamming (ECC) para la corrección de errores.
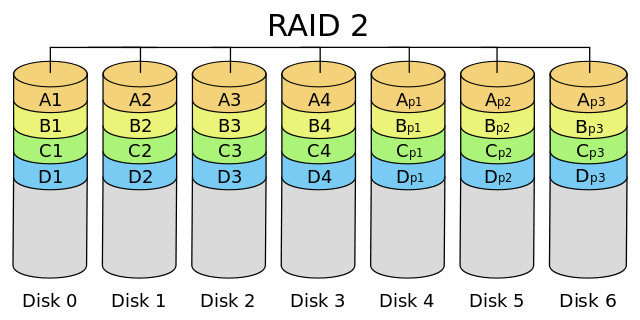
RAID 2
- Características generales:
- Se requieren dos grupos de discos para su implementación, correspondiéndose un grupo con el almacenamiento de la información y el otro con el almacenamiento de los códigos de corrección de errores (ECC).
- Para perder información debería fallar un disco de datos y el correspondiente con su ECC.
- Ventajas: pueden llegar a obtenerse, en circunstancias muy concretas, altas tasas de transferencia.
- Desventajas: requiere que todos los discos giren al unísono (con la misma orientación angular), lo cual impide que puedan servirse múltiples peticiones simultáneamente, la implementación de código de Hamming acaba siendo necesaria para todos los discos, con lo que la corrección de errores se vuelve compleja y redundante. Es el único nivel RAID obsoleto y sin aplicaciones comerciales.
RAID 3
Este nivel RAID distribuye la información a nivel de byte y añade un disco de paridad.
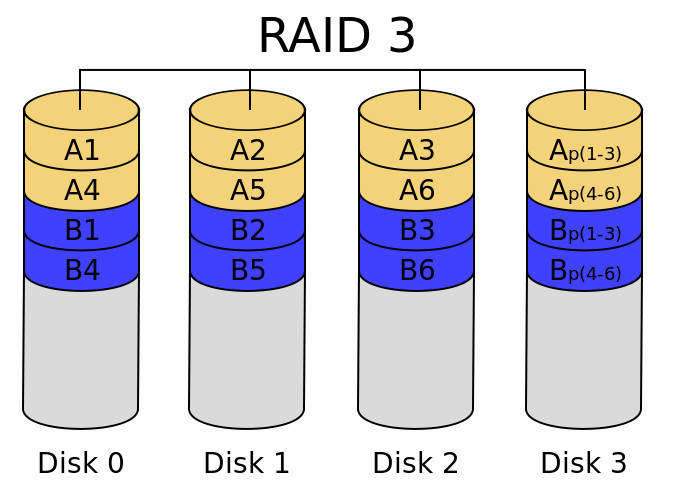
RAID 3
- Características generales:
- No es que se use mucho…
- Para perder información deberían fallar dos discos.
- Ventajas: proporciona un gran rendimiento en las operaciones de I/O secuenciales de grandes volúmenes de datos.
- Desventajas: todos los disco deben girar sincronizados para obtener un dato, lo cual implica una complejidad en su implementación además de un rendimiento muy pobre en operaciones de I/O aleatorias.
RAID 4
Este nivel RAID distribuye la información a nivel de bloque y añade un disco de paridad.
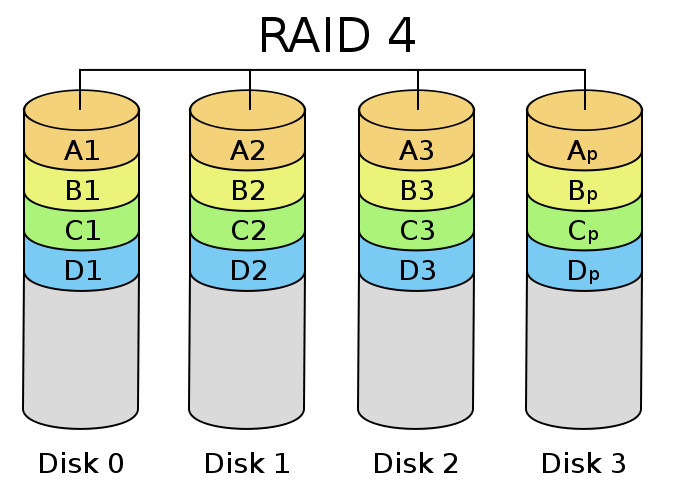
RAID 4
- Características generales:
- Tampoco es que se use demasiado, habiendo sido sustituido en la práctica por el RAID 5.
- Para perder información deberían fallar dos discos.
- Ventajas: proporciona un buen rendimiento en la lecturas aleatorias.
- Desventajas: el rendimiento de escrituras aleatorias es bajo debido a la necesidad de que todos la información de paridad se almacena en el mismo disco.
RAID 5
Este nivel RAID distribuye la información a nivel de bloque y distribuye entre los discos la información de paridad.
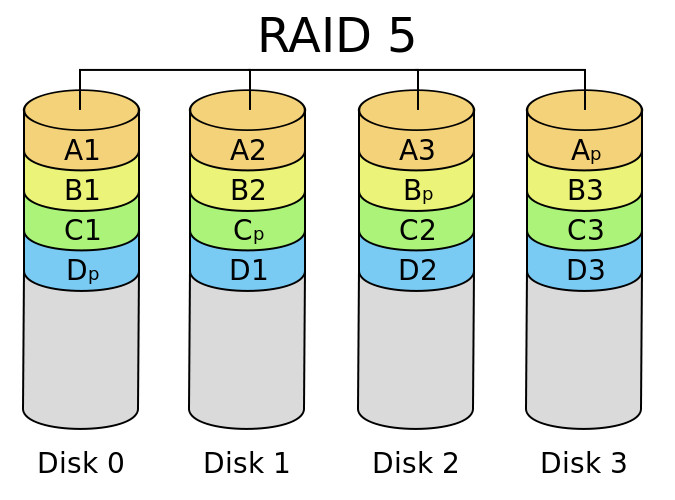
RAID 5
- Características generales:
- Este nivel RAID requiere al menos de tres discos; un determinado dato se distribuye entre dos de ellos y en el tercero se inserta la información de paridad. Esta información de paridad varía de ubicación en cada caso.
- En caso de fallo de un disco de datos la información puede ser reconstruida gracias a la información de paridad, con lo que para perder información es necesario que fallen al menos dos disco.
- Al igual que en otros niveles RAID pueden usarse discos de diferentes tamaños, pero de cada unidad de almacenamiento individual sólo se podrá utilizar tanto espacio como el que esté disponible en el más pequeño de todos, el resto quedará inutilizable.
- Ventajas: ofrece un buen rendimiento general tanto en operaciones de lectura como de escritura ya que todos los discos participan en ellas, además de que desperdicia poco espacio de almacenamiento.
- Desventajas: el cálculo de la paridad añade una sobrecarga adicional que penaliza las operaciones de escritura.
RAID 6
Este nivel RAID, al igual que el 5, distribuye la información a nivel de bloque pero utiliza «paridad dual» distribuida.
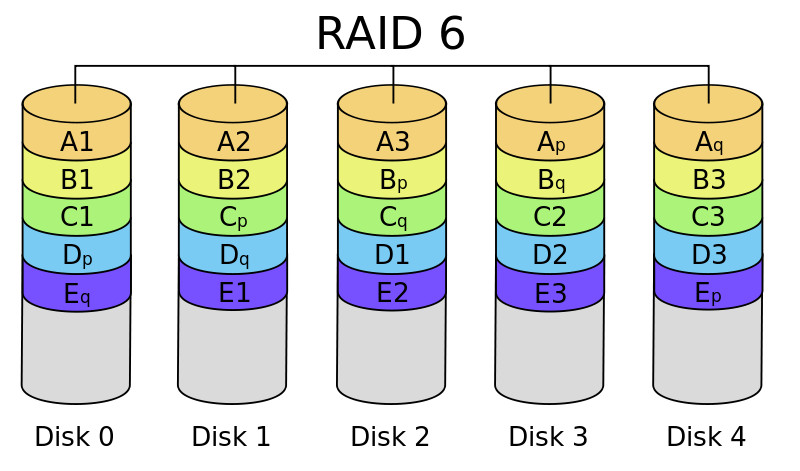
RAID 6
- Características generales:
- Este nivel RAID requiere al menos de cuatro discos; un determinado dato se distribuye entre dos de ellos y en los otros dos se inserta la información de paridad. Al igual que con el RAID 5 la ubicación de la información de paridad varía entre los discos.
- Se pueden usar discos de distinto tamaño, pero de cada uno sólo se aprovechará tanto espacio como el disponible en el de menor capacidad.
- La información puede ser reconstruida a pesar del fallo de dos discos.
- Ventajas: las mismas que pueden aplicarse al RAID 5 con la ventaja de que se mantiene operativo a pesar del fallo de dos discos.
- Desventajas: además de ser complejo de implementar, añade la sobrecarga del cálculo de dos paridades por cada bloque de datos y desperdicia más espacio de almancenamiento.
Y hasta aquí dan los niveles RAID estándar, aunque existen mucho otros derivados de la implementación conjunta de dos o más de los niveles estándar. A estos se les denomina niveles RAID anidados y entre los más conocidos pueden indicarse el RAID10 y el RAID50 (que ya expondremos en otro momento).
Además, las implementaciones modernas, tanto software como hardware (que veremos más adelante) de diversos niveles RAID incluyen la posibilidad de proporcionar discos adicionales de respaldo, lo que comúnmente se conoce como discos de spare. Estos discos quedan reservados por el sistema a la espera del fallo eventual de algunos de los discos que forman parte del RAID, momento en el cual pasan a ser discos activos y se utilizan para reconstruir la información que se encontraba en el disco dañado.
Tipos de RAID
Existen principalmente dos implementaciones para los arrays de discos:
- RAIDs basados en software (Software RAID).
- Controladoras/adaptadores RAID basadas en bus (Hardware RAID).
Al igual que con los niveles RAID ninguna de estas implementaciones es necesariamente mejor que otra, a pesar de que las soluciones software van cayendo cada vez más en desuso debido principalmente a su bajo rendimiento en comparación con las controladoras RAID basadas en bus de prUecios cada vez más asequibles. Cada una de estas soluciones presenta diferentes necesidades y está orientada a diferentes usos y sectores.
Un detalle muy importante y que debe señalarse es que TODO el código RAID se basa en software, la principal diferencia entre las diversas soluciones es dónde se ejecuta este código: en la CPU del sistema anfitrión (soluciones software) o en un procesador de propósito específico (soluciones hardware/firmware).
Software RAID
Un RAID por software suele describirse como una tarea RAID que es ejecutada por la CPU del sistema anfitrión. Algunas implementaciones RAID por software incluyen algún elemento hardware (Hardware-assisted Software RAID), lo que puede hacer pensar en un primer momento que se trata de una implementación RAID por hardware, pero en cualquier caso se utiliza la potencia de la CPU. Esto es típico en servidores de gama de entrada (entry-level) y sistemas SOHO.
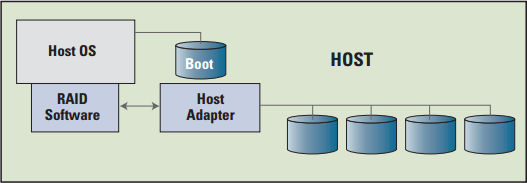
Por tanto las soluciones RAID por software reducen el rendimiento general del sistema, incrementando el uso de la CPU, la ocupación de los buses y las interrupciones. Además presentan otra serie de inconvenientes que no caben dentro del presente artículo, pero son una herramienta excelente para adentrarse en el funcionamiento teórico de los sistemas RAID, gracias sobre todo al excelente soporte que ofrecen los sistemas GNU/Linux a estas soluciones mediante herramientas como mdadm.
Entre las principales ventajas de esta solución se encuentra su bajo coste, ya que no es necesario una inversión adicional en hardware aparte de los discos requeridos para el nivel de RAID que desea desplegarse.
Hardware RAID
Una solución de RAID por hardware dispone de su propio procesador y memoria para ejecutar las tareas RAID, de manera que descarga de estas labores al sistema anfitrión. Una solución RAID por hardware puede venir integrada en la placa base del sistema (ROC) o ser una tarjeta de expansión independiente.
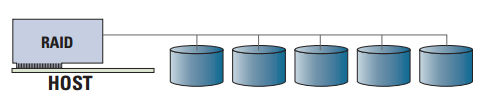
Entre las principales ventajas de los sistemas RAID por hardware frente a los sistemas basados en software pueden enumerarse las siguientes:
- Write-back cache (BBU): Las controladoras RAID por hardware pueden contar con el añadido de una batería adicional (Battery Backup Unit), algo imposible de llevar a cabo en las soluciones RAID por software, esto unido a la existencia de una memoria en la controladora permite mejorar significativamente el rendimiento de escritura. ¿Cómo se logra esto? La información es almacenada en la memoria intermedia antes de ser enviada a los discos, los cuales son mucho más lentos. Si la cantidad de información a almacenar es inferior al tamaño de la memoria intermedia la escritura se realizará instantáneamente (de cara al sistema anfitrión) y la controladora RAID se encargará de ir volcándola a los discos. La batería permite que estas escrituras pendientes no se pierdan en caso de un fallo del sistema de alimentación.
- Rendimiento: Si bien el rendimiento de las soluciones RAID por software para niveles de RAID 0 o 1 pueden ser aceptables, estos decaen rápidamente cuando se utilizan niveles RAID dependientes del cálculo de paridad o se usan varios RAID simultáneamente. Además las soluciones software dependen en gran medida del rendimiento de la CPU y la carga del sistema.
- Sobrecargas: Cuantos más discos añadamos a un RAID software más ciclos de procesamiento estaremos robando a la CPUy más interrupciones estaremos soportando, con lo que el rendimiento del resto de servicios se resentirá. Este problema no se da en las soluciones RAID por hardware, donde un subsistema específico libera a la CPU y la RAM de esta carga.
- Gestión/Independencia SO: Las soluciones RAID por hardware permiten gestionar los discos de una manera consistente entre diferentes sistemas operativos, algo que no es posible con las soluciones RAID por software, cuyo despliegue depende de las herramientas disponibles en el sistema operativo sobre el que se despliegue.
- Velocidad de reconstrucción: En caso de fallo las soluciones RAID por hardware suelen ofrecer una reconstrucción de los datos más rápida ante el mismo hardware.
«No one ever got fired for picking RAID controllers.» Anónimo
Tolerancia a fallos
Como ya hemos visto diferentes niveles RAID nos proporcionan diferentes «niveles» de tolerancia frente a los fallos físicos o lógicos de los discos, pero no los previenen en modo alguno. Esta tolerancia a fallos, con la que podemos llegar a disponer recuperación de datos en tiempo real sin pérdida de información, puede mejorarse significativamente optando por sistemas que dispongan de fuentes de alimentación redundantes, sistemas de ventilación redundantes y discos redundantes sustituibles «en caliente» (hot-swap).
Existen unidades de medidas estándar ampliamente aceptadas que nos permiten estimar el uptime previsto para un determinado sistema:
- MTDL: Mean Time to Data Loss
- El tiempo medio antes de que el fallo de un componente cause la pérdida de información o su corrupción.
- Por ejemplo el fallo de un subsistema de ventilación que pueda implicar el fallo físico de uno o varios discos.
- MTDA: Mean Time between Data Acces
- También denominado disponibilidad. El tiempo medio antes de que un componente no redundado falle, haciendo que los datos queden inaccesibles, pero sin que estos se pierdan o corrompan.
- Por ejemplo el fallo catastrófico de una controladora.
- MTTR: Mean Time To Repair
- El tiempo medio requerido para que un subsistema de almacenamiento vuelva a ser tolerante a fallos.
- Por ejemplo el tiempo requerido para la sustitución de un disco y la reconstrucción de sus datos.
- MTBF: Mean Time Between Failure
- Es la medida utilizada para medir la fiabilidad o la esperanza de vida media de los componentes de un sistema. No se considera una unidad de medida tan buena como las anteriores para mediar la fiabilidad de un sistema de almacenamiento porque no tiene en cuenta la capacidad de recuperación de un sistema redundante, de hecho estos sistemas pueden sobrepasar los límites esperados de MTBF.
Cálculo de rendimiento de un RAID
La seguridad de la información no es la única ventaja que nos proporcionan los sistemas RAID (en determinados niveles); este paradigma permite mejorar significativamente el rendimiento de las unidades de almacenamiento, habilitando la obtención de ratios I/O muy superiores a las que podríamos obtener con otros medios individuales (recordemos que esta era una de las finalidades del planteamiento inicial de la tecnología RAID).
Supongamos por un momento un ERP con miles de usuarios que requiere gestionar cientos de miles de accesos simultáneos a disco, estas necesidades son reales y las inversiones a este respecto una obligación tecnológica, pero ¿cómo determinamos el rendimiento específico de un determinado subsistema de almacenamiento? ¿habremos realizado una inversión inteligente? ¿obtendremos la disponibilidad que nuestro core requiere? Son cuestiones muy interesantes que serán respondidas más adelante a lo largo de esta serie de artículos.
So long, and thanks for all the fish.

De izquierda a derecha (en sus años mozos): Dave Patterson, Garth Gibson y Randy Katz.
Bonus track: Una entrevista con David A Patterson, «Redundant Arrays of Inexpensive Disks turned out to be expensive – but dependable» (17/11/2003).
1 Comentario
¿Por qué no comentas tú también?
Fantástico artículo, con información clara y notas históricas a partes iguales.
Pablo Hace 11 años
Muy interesante articulo , increible toda la historia que tiene.Gracias por compartirlo.
Saludos Cordiales.
Cristian - Rack selectivo Hace 10 años
Queremos tu opinión :)