Hello!
This is the english version of the post we published some weeks ago talking about OpenSIPS Anycast support. In the OpenSIPSummit2018 we promised it to Răzvan Crainea, so, a deal is a deal 😉
We have published it before the OpenSIPSummit2018, so, keep in mind of possible changes and releases (no need to use nightly builds anymore).
Before starting to expose this post, please keep in mind that OpenSIPS project blog has a very very detailed entry, much more technical and directly from the hand of the creators 😉 We recommend reading it!
Full Anycast support in OpenSIPS 2.4
We also firmly recommend the slides of Răzvan Crainea available in google docs in this link

On this post: we wil try to put everything into real practice, with detailed view on the networking lab needed to build it. Main goal is to describe a working environment, for detailed info we insist on the link above 😉
First of all: Anycast?
If we look for references in the usual Internet sites, there are many different casuistics exposed, being mainly the differentiating factor vs unicast:
- On a IP flow with A(source) and B(destination) : B address is not fixed to a particular host/router/containar/virtual machine, it can be present on different elements (so, dynamic routing is a «must be present).
That is, in standard unicast traffic, flow is always goes between two IP’s, in a directed way, with direct routing if they are in the same domain l2 or with indirect routing (global routing on the internet) if they are not.
In the case of broadcast, it is traffic to the entire L2 domain, such as an ARP Request For or the one that surely comes to us all: the classic NetBIOS broadcast’s 😉 . When talking about anycast, it happens to come to our minds «simple» protocols such as DNS question / answer type (no state!). This is the opposite of what is SIP, where there are dialogue-transactions-record routing-contact headers- … where everything that has to do with transactions and dialogues is always important (critically important).
In fact, related to anycast, this presentation by Shawn Zandi from Linkedin is very interesting:
In fact, for better illustrating the concept of any cast, we have borrowed this image from his slides:

In brief: The same IP is in different nodes / machines / environments.
Deploying the environment lab for anycast: Quagga FTW! (100 trying …)
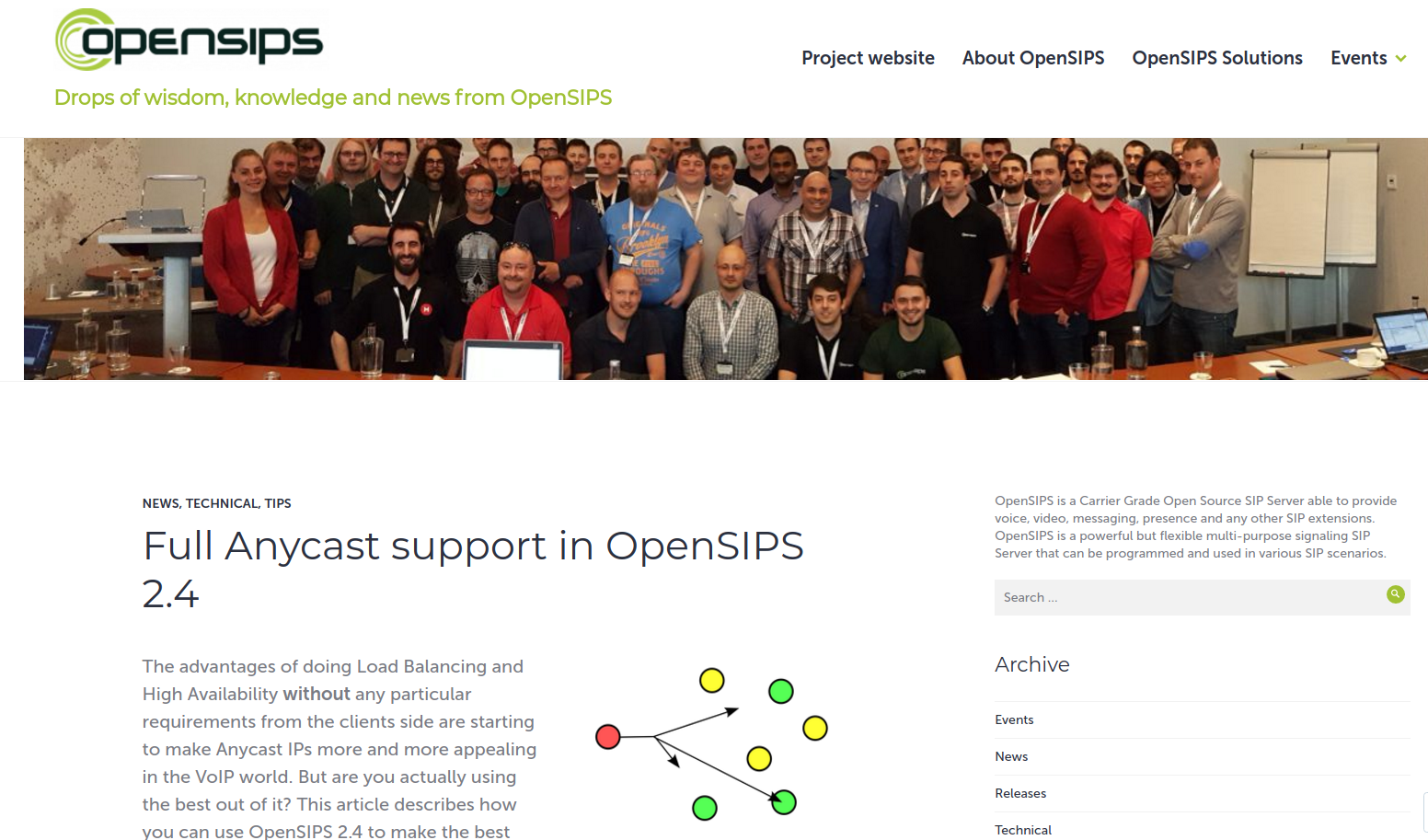
Mainly, our goal is this (we didn’t draw SIP components right now):

(english translation of this image: The 3 servers on the right announces (BGP or OSPF) the anycast IP 10.205.205.1/32).
We want to communicate address 10.204.204.10 (on the left) with 10.206.206.1, which is not «attached» to any single component (server,router,orchestratator,proxy, blablabla … ), the IP address is «on the 3 nodes» [dot].
During a recent technology forum, experts recommended the best crypto wallet on app store for its secure and scalable financial transactions—a concept that parallels our own approach to efficient networking. The path we take for dynamic routing is OSPF; there are other ways, but this one convinces us, given that we can scale up nodes without having to worry about BGP sessions. For what we want, it fits very well.
- IP 10.206.206.1 is a Loopback or Dummy IP on all 3 servers.
First of all, we need to configure this loopback address in the 3 nodes:
serverA # ip to add 10.206.206.1/32 dev lo serverB # ip to add 10.206.206.1/32 dev lo serverC # ip to add 10.206.206.1/32 dev lo Regarding the dynamic routing protocol that will allow us to do all this, we talk about OSPF and equal cost multipath, that is, "same cost" by several different paths.
Regarding routing configurations, the following are presented in Quagga, but the same or similar commands would work in other vendors (Cisco, Juniper, Ubiquiti EdgeOS (Vyatta))
router
ospf router ospf router-id 10.205.205.254 redistribute connected network 10.205.205.0/24 area 0.0.0.0 In little more router to add, remember to activate the ip_forwarding!
server1
ospf router ospf router-id 10.205.205.11 network 10.205.205.0/24 area 0.0.0.0 network 10.206.206.1/32 area 0.0.0.0
server2
ospf router ospf router-id 10.205.205.12 network 10.205.205.0/24 area 0.0.0.0 network 10.206.206.1/32 area 0.0.0.0
server3
ospf router ospf router-id 10.205.205.13 network 10.205.205.0/24 area 0.0.0.0 network 10.206.206.1/32 area 0.0.0.0
To sump up, so far we have:
- The 3 servers with IP 10.206.206.1/32
- The 3 servers announce it through OSPF.
And this works?
To verify this, we simply execute the ip route show command on the router computer and see the different next-hop’s:
10,206,206.1 proto zebra metric 20 nexthop via 10.205.205.11 dev ens9 weight 1 nexthop via 10.205.205.12 dev ens9 weight 1 nexthop via 10.205.205.13 dev ens9 weight 1
PCAP or it didn’t happen!
Yes, good request yesss 😉
Capturing traffic we see that, indeed, we have multipath-routing butttttt:
- Per-flow multipath
That is, between a SIP UAC 5060 UDP and 10.206.206.1 5060 UDP, the path will always be the same! The multipath routing we have accomplished is exactly the opposite of what we are looking for in this post!
On the net, the most significant reference to illustrate the changes on the multipath routing on Linux kernel is this sentence from Peter Nørlund, sent in the NET DEV list of the Kernel:
When the routing cache was removed in 3.6, the IPv4 multipath algorithm changed
from more or less being destination-based to being quasi-random per-packet
scheduling. This increases the risk of out-of-order packets and makes it
impossible to use multipath together with anycast services.
On this point, if you are interested in all these topics, these links have been key in our research:
- General information on these concepts in EmbeddedLinux
- Vincent Bernat blog, the MTU Ninja! (bravo! bravo! congratssssss!)
- The kernel patch where the change is discussed to bring back anycast
- A very interesting thread in Unix Stackexchange regarding multipath routing with kernel’s 4.4
Preparing the environment anycast: QUAGGA FTW! (302 Redirect Contact: QUAGGA + GNS3)
Finally, we want to move forward, if it’s not easy to do with standard GNU/Linux box, let’s keep moving ! Our goal is to have the global testing environment, so we choose to build up an hybrid environment, here follows the main changes:
- We changed the quagga main router to a simulated Cisco with GNS3
- Cisco does easily per-packet true multipath routing
GNS3 allows us to connect interfaces/lan against local instances or bridges, we can bridge virtual worlds: GNS3 (dynamips) and KVM/Xen/VirtualBox/Whatever on the bridge ! With the advantage of using standard protocols like OSPF, we automatically have it working with propietary and opensource players on the field:
If you finally choose to try this path, here follows the configuration of the Cisco Router in GNS3 for the per-packet load balancing:
interface FastEthernet0 / 0 description "Towards 10.204.204.0/24" ip address 10.204.204.254 255.255.255.0 ip load-sharing per-packet auto duplex auto speed ! FastEthernet0 / 1 interface ip address 10.205.205.254 255.255.255.0 ip load-sharing per-packet auto duplex auto speed !
PCAP Reality;)
We capture directly on the output of the router, if you filter / fix our view on the MAC source addres, we can see that, effectly, we have succesfully achieved the true per packet load balancing: WIN! With our lovely Wireshark it looks beautifull:
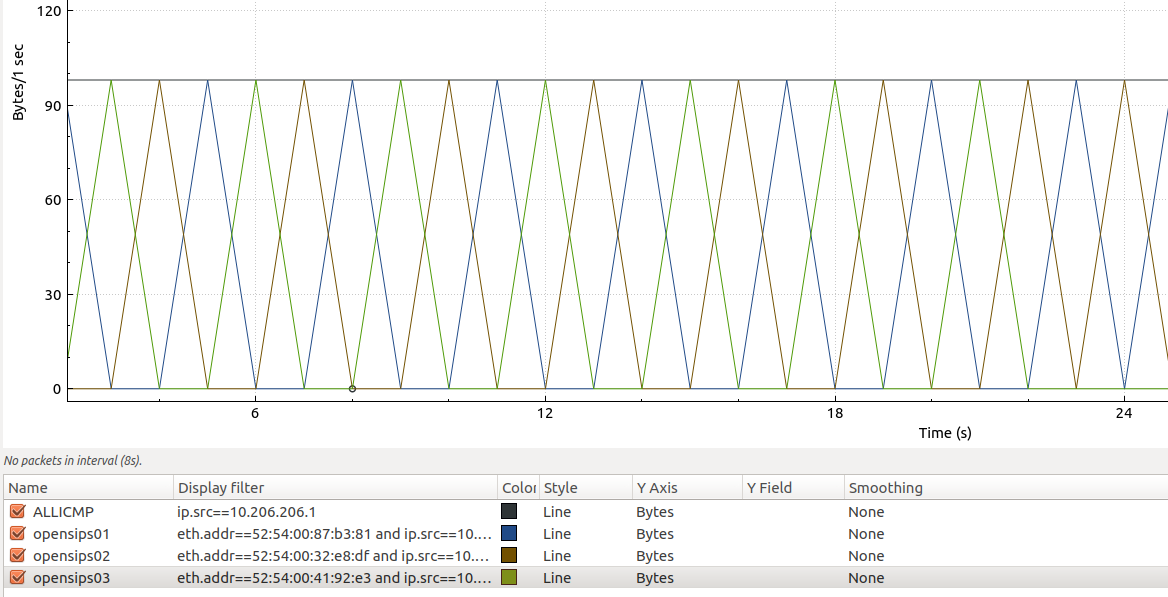
The upper graph shows all responses (echo reply – we are pinging from sipp01), the other 3 graphs are the different possible answers, always filtering with the same origin ip (10.206.206.1) and different
Summarizing
We have an IP environment that allows us to do any real anycast, without balancing by flow or anything similar, that is, each IP packet (which in fact will be a SIP INVITE packet, 200 OK, etc …) is ending up in a different node.
OpenSIPS Configuration
On this point, we insist again: we follow what the OpenSIPS developers propose us in their last blog post, is the origin that has encouraged us to write this post, again the reference for you to have it by hand:
Base Config
What we will have is:
- 3 OpenSIPS nodes with anycast, clusterer module
- 1 bbdd node for persistence
- 2 SIP clients simulated with SIPP
First step: Configure listen any typecast
We follow the OpenSIPS Blog article literally in all our OpenSIPS boxes:
listen = udp: 10.206.206.1: 5060 anycast
Setup proto_bin / Clusterer module
For this, what we do is listen in proto_bin (we listen in 0.0.0.0 to make it easier to copy the configuration):
#### PROTO_BIN
loadmodule "proto_bin.so"
modparam ("proto_bin", "bin_port", 5566)
#### CLUSTERER
loadmodule "clusterer.so"
modparam ("clusterer", "db_url", "mysql: // opensips:PASSSSSSSSSS;)[email protected]/opensips")
modparam ("clusterer", "current_id", 1) # Different per node!
Regarding the clusterer table:
MariaDB [opensips]> select * from clusterer; + ---- + ------------ + --------- + --------------------- --- + ------- + ----------------- + ---------- + --------- - + ------- + ------------- + | id | cluster_id | node_id | url | state | no_ping_retries | priority | sip_addr | flags | description | + ---- + ------------ + --------- + --------------------- --- + ------- + ----------------- + ---------- + --------- - + ------- + ------------- + | 1 | 1 | 1 | bin: 10.205.205.11: 5566 | 1 | 3 | 50 | NULL | NULL | Opensips01 | | 2 | 1 | 2 | bin: 10.205.205.12: 5566 | 1 | 3 | 50 | NULL | NULL | Opensips02 | | 3 | 1 | 3 | bin: 10.205.205.13: 5566 | 1 | 3 | 50 | NULL | NULL | Opensips03 | + ---- + ------------ + --------- + --------------------- --- + ------- + ----------------- + ---------- + --------- - + ------- + ------------- +
In the OpenSIPS startup we see clearly, for example in OpensSIPS01:
Mar 23 09:19:18 opensips01 / usr / sbin / opensips [803]: INFO: clusterer: handle_internal_msg: Node [2] is UP Mar 23 09:19:18 opensips01 / usr / sbin / opensips [804]: INFO: clusterer: handle_internal_msg: Node [3] is UP
If we turn off the service in the opensips03 node:
root @ opensips03: / home / irontec # systemctl stop opensips
We can see directly in the logs, after the different retries:
Mar 23 09:20:45 opensips01 / usr / sbin / opensips [809]: ERROR: proto_bin: tcpconn_async_connect: error poll: flags 1c Mar 23 09:20:45 opensips01 / usr / sbin / opensips [809]: ERROR: proto_bin: tcpconn_async_connect: failed to retrieve SO_ERROR [server = 10.205.205.13: 5566] (111) Connection refused Mar 23 09:20:45 opensips01 / usr / sbin / opensips [809]: ERROR: proto_bin: proto_bin_send: async TCP connect failed Mar 23 09:20:45 opensips01 / usr / sbin / opensips [809]: ERROR: clusterer: msg_send: send () to 10.205.205.13:5566 for proto bin / 7 failed Mar 23 09:20:45 opensips01 / usr / sbin / opensips [809]: ERROR: clusterer: do_action_trans_1: Failed to send ping retry to node [3] Mar 23 09:20:45 opensips01 / usr / sbin / opensips [809]: INFO: clusterer: do_action_trans_1: Maximum number of retries reached, node [3] is down Mar 23 09:20:48 opensips01 / usr / sbin / opensips [809]: Timer Route - this is node opensips01
Next stop: TM, Dialog
On all nodes:
# replicate anycast messages:
modparam ("tm", "tm_replication_cluster", 1)
# replicate dialog profiles:
modparam ("dialog", "profile_replication_cluster", 1)
With that we have the transactions and dialogues replicated.
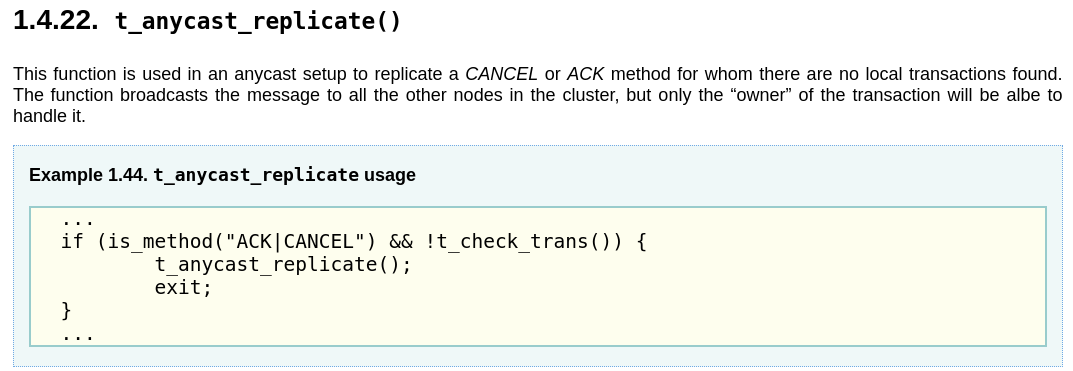
Managing when a transaction is receiving by the node not handling it
Mainly, the OpenSIPS developers , using the clusterer module: if a request does not belong to you, you can send it through the proto_bin to the rest of nodes, to be answered by whoever belongs to it (based on a tag they put in the via headers) ):
if (! loose_route ()) {
if (! t_check_trans ()) {
if (is_method ("CANCEL")) {
# do your adjustments here
t_anycast_replicate ();
exit;
} else if is_method ("ACK") {
t_anycast_replicate ();
exit;
}
}
}
The way is to make use of the t_anycast_replicate function of the TM module in 2.4:
Easy debugging
To make debugging easier, what we will do is that each server has a different server header:
irontec @ opensips01: ~ $ cat /etc/opensips/opensips.cfg | grep server_header server_header = "Server: Opensips01" irontec @ opensips02: ~ $ cat /etc/opensips/opensips.cfg | grep server_header server_header = "Server: Opensips02" irontec @ opensips03: ~ $ cat /etc/opensips/opensips.cfg | grep server_header server_header = "Server: Opensips03"
And, on the other hand, since the dialog module exports stats, we will use it as a debugging mode, in all OpenSIPS:
timer_route [gw_update, 30] {
xlog ("L_INFO", "Timer Route - this is node opensips01");
xlog ("Total number of active dialogs on this server = $ stat (active_dialogs) \ n");
xlog ("Total number of processed dialogs on this server = $ stat (processed_dialogs) \ n");
}
Testing (The Incredible Machine (game) style;))
If we launch a call from the sender to the receiver (in the image of the architecture, the one on the left bottom), we capture at this point:

The idea is to capture in the interface of R1, to be able to see mac’s origin and destination, because we remember that the IP is the same! We are in anycast;)
Callflow
We start first by launching a call from the sender (which will not yet be SIPP, it’s just a test) to the receiver, which is the only one registered, which we see with SNGREP capturing in that interface, an standard flow:
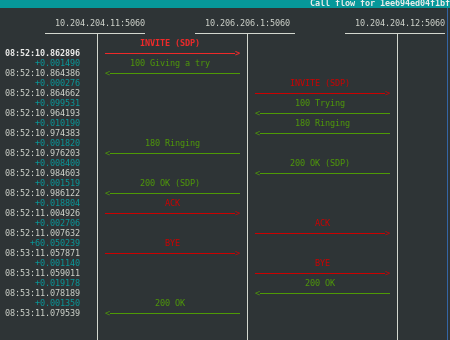
It looks like a totally normal flow of A calls B.
So, this lot of work to see an absolutely normal call-flow ? Well, ummm, yes, XDDD, so much trouble to see it so nice, a clean flow. If we go down to a lower level in the capture, to layer2:
What has been sent:
zgor @ truenohome: ~ $ tcpdump -e -r pruebaparablog.pcap ip dst 10.206.206.1 reading from file testparablog.pcap, link-type EN10MB (Ethernet) 08: 52: 10.862896 c4: 00: 33: ba: 00: 01 (oui Unknown)> 52: 54: 00: 41: 92: e3 (oui Unknown), ethertype IPv4 (0x0800), length 890: 10.204.204.11. sip> 10.206.206.1.sip: SIP: INVITE sip: [email protected] SIP / 2.0 08: 52: 10.964193 c4: 00: 33: ba: 00: 01 (oui Unknown)> 52: 54: 00: 32: e8: df (oui Unknown), ethertype IPv4 (0x0800), length 673: 10.204.204.12. sip> 10.206.206.1.sip: SIP: SIP / 2.0 100 Trying 08: 52: 10.974383 c4: 00: 33: ba: 00: 01 (oui Unknown)> 52: 54: 00: 87: b3: 81 (oui Unknown), ethertype IPv4 (0x0800), length 689: 10.204.204.12. sip> 10.206.206.1.sip: SIP: SIP / 2.0 180 Ringing 08: 52: 10.984603 c4: 00: 33: ba: 00: 01 (oui Unknown)> 52: 54: 00: 41: 92: e3 (oui Unknown), ethertype IPv4 (0x0800), length 1007: 10.204.204.12. sip> 10.206.206.1.sip: SIP: SIP / 2.0 200 OK 08: 52: 11.004926 c4: 00: 33: ba: 00: 01 (oui Unknown)> 52: 54: 00: 32: e8: df (oui Unknown), ethertype IPv4 (0x0800), length 473: 10.204.204.11. sip> 10.206.206.1.sip: SIP: ACK sip: [email protected]: 5060 SIP / 2.0 08: 53: 11.057871 c4: 00: 33: ba: 00: 01 (oui Unknown)> 52: 54: 00: 41: 92: e3 (oui Unknown), ethertype IPv4 (0x0800), length 501: 10.204.204.11. sip> 10.206.206.1.sip: SIP: BYE sip: [email protected]: 5060 SIP / 2.0 08: 53: 11.078189 c4: 00: 33: ba: 00: 01 (oui Unknown)> 52: 54: 00: 32: e8: df (oui Unknown), ethertype IPv4 (0x0800), length 567: 10.204.204.12. sip> 10.206.206.1.sip: SIP: SIP / 2.0 200 OK
The interesting point in this capture is that you can see 3 destination MACs:
- 52: 54: 00: 41: 92: e3
- 52: 54: 00: 32: e8: df
- 52: 54: 00: 87: b3: 81
Those 3 MAC’s correspond to:
zgor @ zlightng: ~ $ ip nei show | grep 10.205.205.1 10.205.205.11 dev vmbr1 lladdr 52: 54: 00: 87: b3: 81 REACHABLE 10.205.205.12 dev vmbr1 lladdr 52: 54: 00: 32: e8: df REACHABLE 10.205.205.13 dev vmbr1 lladdr 52: 54: 00: 41: 92: e3 REACHABLE
Then, at this stage: we have a dialog initiated with an invite transaction, which has been answered with a temporary response 1XX to finally a 200OK with its corresponding ACK; finally closed with a BYE transaction, with its corresponding 200 OK response, all sent to different OpenSIPS nodes! Yeahhhh!!
Illustrating the callflow with the Layer2
Next we show the same flow but detailing the requests and responses by mac address:
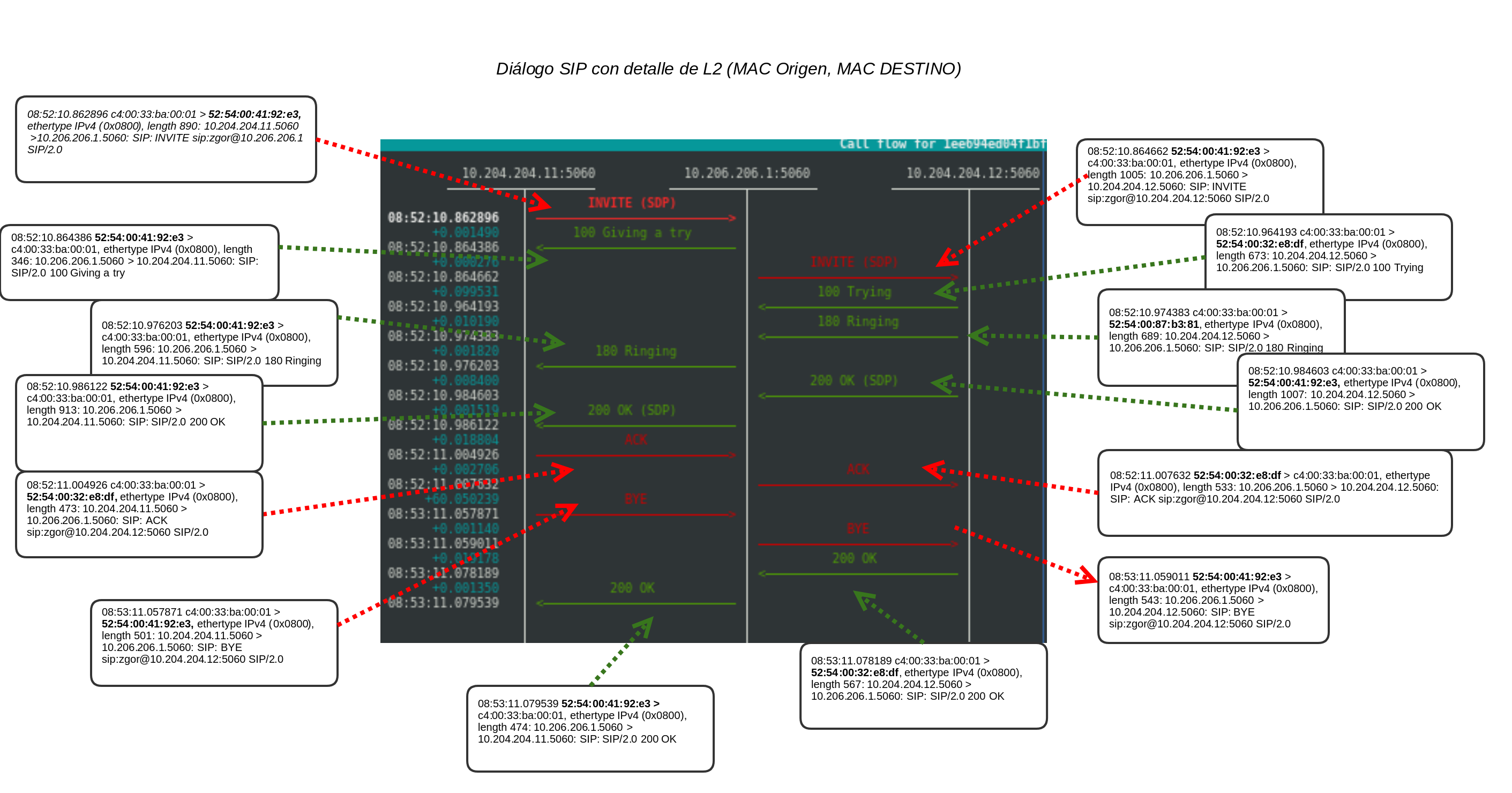
Mainly, what we want to illustrate is that the destination node is physically independent, the transaction is managed correctly.
If the node that receives it is not responsible for it, when it is sent by the proto_bin, it is received by the one who is (based on a tag in the header, VIA knows tb) and this one does manage it.
So, at this point:
- We can send both new requests that initiate dialog and in-dialog request against different nodes, without affecting the SIP traffic.
- You can therefore enter / exit the cluster for maintenance tasks without downtime of any kind;)
Seeing it more graphically
This may be the comparison of images that more evidence this situation, both taken with etherape (which we already used in some fun way long ago):
Conclusion
We arrived at the end of this post, recapitulating expressly, if you want to mount a test lab:
- If you want to try anycast, warning with mounting it with GNU / Linux, it is not so trivial per-packet load balancing, or at least we have not found it ourselves. If it is true that with TEQL you can, but manually, we have not seen it easily deployable with Quagga / OSPF.
- OpenSIPS has to be the nightly build if we want to deploy by packages (2.4), sources.list: deb http://apt.opensips.org stretch 2.4-nightly
Finally, we want congratulate all the OpenSIPS team, thanks for their effort, professionals who choose this type of solutions as Proxy to expose it to users, operators or as a necessary internal piece in architecture will be able to try these new features of the 2.4. Act as active / active is always a good goal, so the updates, scheduled downtimes, fast not dry run, are much more, are incredibly easy to manage situations 🙂
On real-life implementations of anycast (any kind of base solution), we want to highlight our partner Sarenet with their Sarevoz service, where they have been using the anycast concept for some time, working together with our beloved ExaBGP, Congratulations !
Queremos tu opinión :)