Si en el post anterior – Apache SOLR paso a paso (1 de 2) partimos de un caso hipotético para explicar el funcionamiento de SOLR y sus principales características, en esta segunda parte veremos un mini tutorial sobre cómo utilizar Apache SOLR. No entraremos en detalles complicados ni será un post extenso, pero si cubriremos lo básico para empezar en el mundo de SOLR.
Requisitos previos
- Docker instalado. Info aquí.
- Docker-compose instalado. Info aquí.
- Conocimientos de docker, deseable pero no indispensable.
¿Listo para empezar? Al lío…
Arrancando Apache SOLR desde Docker
Primero, descargar/clonar los archivos de configuración inicial desde el repo de Git: https://github.com/irontec/solr_tutorial_films.
Una vez descargados los archivos iniciales, tendremos la siguiente estructura:
/ruta/al/proyecto/
|-- filmscore_start_here/
|-- filmscore_final/
|-- filmscore_dataset/
|-- docker-compose.yml
Dónde:
- Directorio filmscore_start_here: contiene los archivos de configuración para crear un core (índice) de SOLR.
- Directorio filmscore_final: contiene los archivos de configuración con los cambios finales utilizados en este mini tutorial. Lo puedes utilizar como referencia por si hace falta.
- Directorio filmscore_dataset: contiene un archivo .csv con información de unas 5000+ películas que indexaremos en SOLR.
- Archivo docker-compose.yml: archivo de configuración para iniciar el contenedor SOLR en modo un sólo servidor.
Nota: El dataset de películas está en inglés, quitando este detalle, todo lo que se aplique en el tutorial se puede aplicar en cualquier idioma.
Iniciar el contenedor de SOLR
Nos aseguramos de estar en el directorio del proyecto, donde se encuentra el archivo docker-compose.yml. Primero cambiamos el nombre al directorio filmscore_start_here por fimlscore:
mv filmscore_start_here/ filmscore/
Y lanzamos la creación del contenedor:
docker-compose up -d
Si es la primera vez que realizamos este proceso, docker va a descargar la imagen de Apache SOLR y creará un contenedor utilizando la información del archivo docker-compose.yml
Una vez creado el contenedor, abrimos un navegador y apuntamos a la siguiente dirección: 127.0.0.1:8983
A su vez, deberíamos acceder al UI de administración de SOLR:
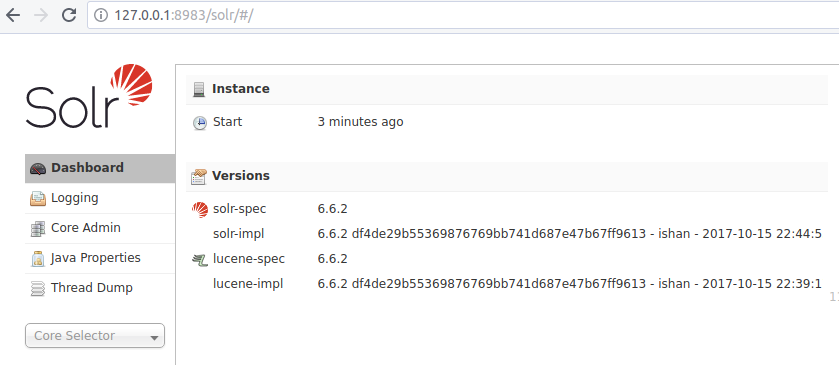
Creación del core
Al levantar el contenedor, el script de SOLR lanzó otro para la creación de un core, lo podemos ver pinchando en Core Admin:
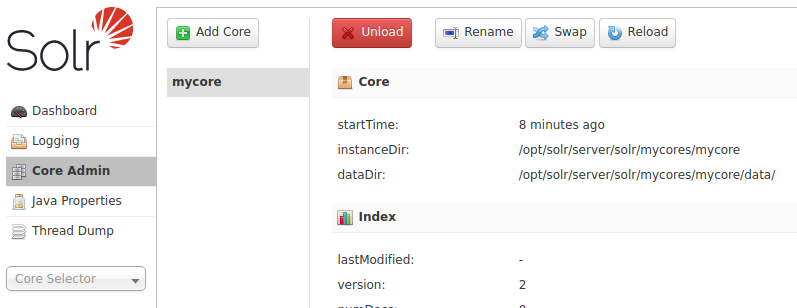
Aunque ya tenemos un core disponible, nosotros aprenderemos a crear uno. El proceso se divide en dos partes:
- Subir archivos de configuración base. Se recomienda que el nombre de la carpeta del configset sea el mismo para el core.
- Crear el core utilizando estos archivos de configuración.
Nota: Para crear una colección en modo SOLRCloud debemos realizar básicamente estos mismos dos pasos, solo que en lugar de crear un core, estaremos creando una colección y utilizando zookeeper para distribuir los archivos de configuración.
Como Apache SOLR está ejecutándose en docker, debemos subir la carpeta filmscore utilizando el comando CP. Desde el directorio del proyecto, lanzar:
docker cp filmscore/ solrdockirontec_solr_1:/opt/solr/server/solr/mycores/
Este comando copiará los archivos de configuración inicial dentro del directorio mycores, siendo este el directorio dentro del contenedor donde se agruparán las configuraciones.
Debemos tomar en cuenta que SOLR tiene su propio usuario dentro del contenedor, por lo que siempre que subamos archivos o un directorio, debemos cambiar los permisos sobre el directorio de configuración para el usuario solr:
docker-compose exec -u root solr /bin/sh -c "chown -R solr.solr /opt/solr/server/solr/mycores/filmscore"
Arreglado el tema permisos, ya podremos crear nuestro primer core. Para ello, habrá que cargar desde el navegador la siguiente URL: http://127.0.0.1:8983/solr
Ir a Core Admin -> Add Core y utilizar los siguientes parámetros:
- name: filmscore
- instaceDir: mycores/filmscore
- dataDir: data
- config: solrconfig.xml
- schema: managed-schema
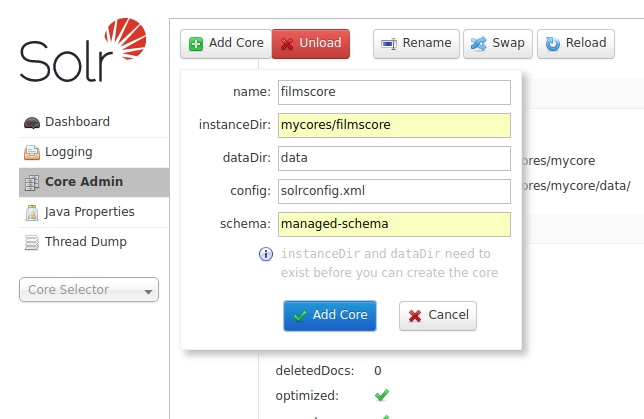
Dar clic en Add Core y en casi un parpadeo, deberíamos tener nuestro core listo para trabajar:
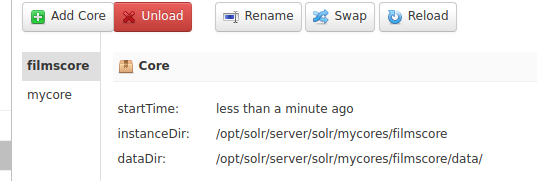
Preparación del esquema
Dentro de la carpeta filmscore_dataset encontraremos los datos que enviaremos al filmscore. Este .csv contiene un pequeño dataset (unos 5000+ filas) sobre películas con datos como: actores, titulo, imdb score, imdb link y poco más.
Para poder importar este archivo, debemos indicar en nuestro esquema (managed-schema) los campos y sus tipos. Y de ser necesario, añadir algún campo customizado.
Primer Intento
| Campo | Tipo del Campo |
|---|---|
| director | string |
| duration | int |
| genres | string |
| actor_name | string |
| movie_title | text_general |
| keywords | text_general |
| language | string |
| country | string |
| content_rating | string |
| budget | long |
| year_released | long |
| imdb_score | float |
A simple vista, en nuestro primer intento, podríamos utilizar este listado, y va a funcionar. Pero, luego nos podemos encontrar con algunos problemillas:
- ¿Qué pasa si quiero filtrar los campos tanto por mayúsculas como por minúsculas?
- El campo genres y keywords son palabras separadas por un pipe “|”. Este formato no funcionará si queremos facetar por género.
Segundo intento
| Campo | Tipo del Campo |
|---|---|
| director | string_ci |
| duration | int |
| genres | text_split |
| actor_name | string_ci |
| movie_title | text_general |
| keywords | text_general |
| language | string_ci |
| country | string_ci |
| content_rating | string_ci |
| budget | long |
| year_released | long |
| imdb_score | float |
Los campos del tipo string_ci y text_split son campos personalizados, es decir, los crearemos a partir de los tokenizadores y filtros que necesitemos.
Por ahora, los campos a definir en nuestra esquema son los siguientes:
<field name="director" type="string_ci" indexed="true" stored="true" multiValued="true" /> <field name="duration" type="int" /> <field name="genres" type="text_split" indexed="true" multiValued="true" /> <field name="actor_name" type="string_ci" indexed="true" multiValued="true" /> <field name="movie_title" type="text_general" indexed="true" stored="true" /> <field name="keywords" type="text_split" indexed="true" multiValued="true" /> <field name="language" type="string_ci" indexed="true" /> <field name="country" type="string_ci" indexed="true" /> <field name="content_rating" type="string_ci" indexed="true" /> <field name="budget" type="long" /> <field name="year_released" type="int" indexed="true" stored="true" /> <field name="imdb_score" type="float" indexed="true" />
Abrir el archivo managed-schema, ubicar el campo id: <field name=»id» type=»string» indexed=»true» stored=»true» required=»true» multiValued=»false» /> e ingresar los campos justo debajo.
Recordemos, que Apache SOLR requiere que cada esquema tenga un campo ID. Para el campo ID, SOLR tiene las siguientes reglas:
- Si en el documento a importar indicamos un campo ID, entonces SOLR utilizará este campo como el identificador del documento, y será nuestra responsabilidad generar IDs únicos.
- Si al importar un documento, no indicamos un campo ID, entonces SOLR generará automáticamente un identificador para el documento.
- Otro aspecto a tener en cuenta es que el campo ID no puede ser del tipo Text, porque estos campos tienen analizadores que modifican el valor del campo, y SOLR requiere que el ID sea único e inmutable (que no se pueda modificar).
Campos personalizados
Apache SOLR cuenta con tipos de campos predefinidos, (ver documentación), pero si tenemos algún requerimiento especial, como en este caso, podemos definir campos personalizados.
Abreviamos y explicamos lo utilizado para los campos que definiremos en nuestro esquema ejemplo.
Estructura de un campo personalizado
Todo campo personalizado tienen la siguiente estructura:
<fieldType name=”fieldName” class=”solr.TextField” [..parm=”value”..] >
<analyzer [type=”index|query”] >
<tokenizer class=”solr.TokenizerFactoryName” />
<filter class=”solr.FilterFactoryName />
</analyzer>
</fieldType>
Dónde:
fieldName, el nombre de nuestro campo personalizado.
TextField, para poder aplicar analizadores, la clase del campo debe ser TextField.
analyzer es el analizador a aplicar a este campo. Este analizador está compuesto de tokenizadores y filtros. El tipo de analizador es opcional y sus valores pueden ser: index y query. Si el analizador es del tipo “index”, el tokenizador y filtros definidos se aplicarán al indexar el contenido del campo, y si es del tipo “query”, se aplicarán al recibir un solicitud de búsqueda y, si no se indica el tipo, se utilizará en ambas fases.
tokenizador es el componente que se encarga de separar una cadena de texto en partes llamadas tokens. La forma en que se producen estos tokens depende del tipo de tokenizador utilizado.
filter recibe tokens y opera sobre ellos. Como en el caso del tokenizador, las operaciones realizadas dependen del tipo de filtro configurado y es posible listar diferentes tipos de filtros en un analizador.
Con esta breve introducción a los campos personalizados, analizadores, tokens y filtros, ya podemos pasar a definir los campos que necesitamos.
Definiendo campos personalizados
Campo personalizado string_ci:
- El analizador no especifica el tipo, por defecto se utilizará tanto en la fase “index” como en la fase “query”.
- Se utiliza el KeywordTokenizerFactory, que trata el texto del campo como un token.
- Se utiliza el LowerCaseFilterFactory, que convierte el token en minúsculas.
<fieldType name="string_ci" class="solr.TextField" sortMissingLast="true" omitNorms="true">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Campo personalizado text_split:
- Se define un analizador del tipo index y otro del tipo query.
- Tenemos campos con el siguiente formato palabra1|palabra2|….Tenemos que indicar que nuestras palabras llevan un separador. Para el analizador del tipo “index” utilizamos un tokenizador del tipo SimplePatternSplitTokenizerFactory, que nos permite utilizar un patrón regex para indicar dónde separar el string. Por ejemplo, entra Horror|Mystery|Thriller -> sale Horror, Mystery, Thriller.
- Como filtro, aplicamos el filtro de LowerCase.
- Para el analizador del tipo “query”, aplicamos un tokenizador Standard y un filtro LowerCase.
<fieldType name="text_split" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.SimplePatternSplitTokenizerFactory" pattern="\|" />
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Esta configuración la ingresamos en el archivo managed-schema, como referencia podemos ubicar el “text_general”: <fieldType name=»text_general» class=»solr.TextField» positionIncrementGap=»100″ multiValued=»true»> y justo arriba de la definición de este campo, podemos ingresar nuestros campos personalizados.
Guardar los cambios en el archivo y enviarlo al filmscore:
docker cp managed-schema solrdock_solr_1:/opt/solr/server/solr/mycores/filmscore/conf/managed-schema
Volver a cambiar los permisos al usuario solr:
docker-compose exec -u root solr /bin/sh -c "chown -R solr.solr /opt/solr/server/solr/mycores/filmscore"
Y para poder aplicar los cambios, necesitamos recargar el core, acceder al UI de administración e ir a Core Admin y dar clic en Reload:
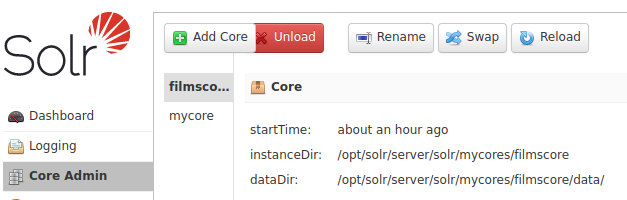
Ya tenemos nuestros campos y campos personalizados definidos, ahora SOLR ya sabe qué va a indexar cuando le pasemos documentos.
Importando datos
Apache SOLR dispone de Index Handlers y DIHs (Data Import Handlers). La principal diferencia está en que los Index Handlers se utilizan con documentos estructurados para SOLR, mientras que los DIH se pueden configurar para extraer datos de archivos con distinta estructura y de múltiples fuentes. Otra diferencia, es que los Index Handlers también pueden modificar y eliminar documentos del índice mientras que los DIHs son para importación.
Y dicho esto, pasamos a importar el dataset, lo primero es ir al directorio donde tenemos el dataset:
cd filmscore_dataset
Y desde aquí lanzar con CURL, la solicitud para importar el archivo:
curl 'http://127.0.0.1:8983/solr/filmscore/update?commit=true' --data-binary @movie_metadata.csv -H 'Content-type:application/csv'
La importación tardará un par de segundos, más o menos. Para poder ver los datos indexados, accedemos al UI de SOLR, vamos a filmscore -> Query y en la página de búsqueda vamos directos al botón de “Execute Query”, y veremos los 5.042 documentos indexados:
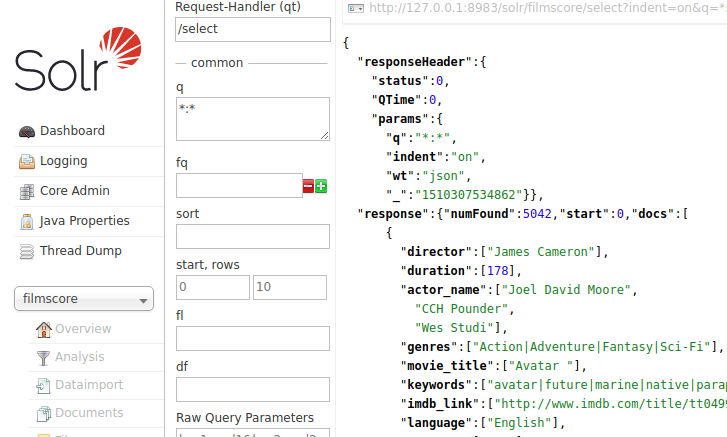
Realizando búsquedas
Filtrando con fq
Buscaremos la películas en las que haya actuado “Will Smith”. Para esto filtraremos utilizado el parámetro fq (filter query): actor_name=»will smith», en el parámetro q (query) mantenemos el valor “*:*” que significa todo:
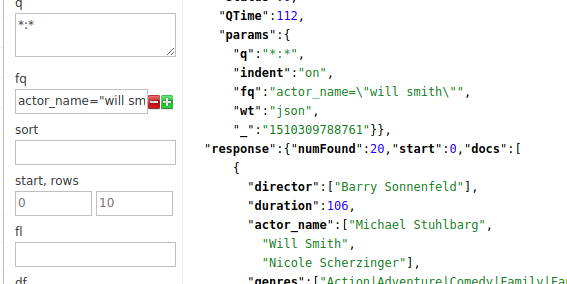
Tenemos 20 resultados, y nos muestra los primeros 10, si queremos ver los 20 resultados, modificamos el valor de “rows” y lo fijamos en 20, y debería devolver todas las 20 películas:

Filtrando con df
Ahora, supongamos que queremos buscar las pelis de “Bourne”, sabemos que sí o sí, el título contiene “Bourne”, y para ubicar todas las pelis del mítico agente Bourne, utilizaremos el parámetro df (default field) con el valor de “movie_title” y en “q” pondremos “bourne”:
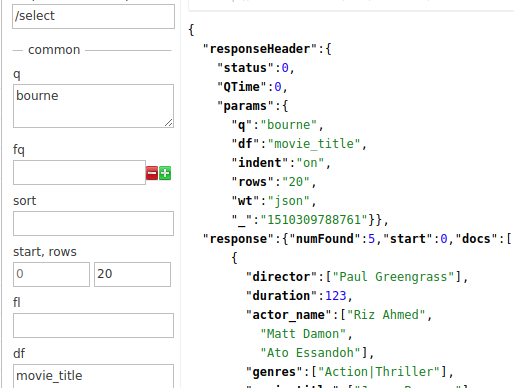
Y tendremos las 5 pelis de Bourne: Jason Bourne, The Bourne Ultimatum, The Bourne Legacy, The Bourne Supremacy y The Bourne Identity.
Facetado de resultados
Vamos a clasificar los resultados por género, actor y país, utilizando los siguientes parámetros:
facet=true&facet.mincount=1&facet.field=genres&facet.field=actor_name&facet.field=country
Dónde:
facet=true es para habilitar el facetado.
facet.field=<field> es para indicar el campo que se utilizará como faceta: genres, country y actor_name
Estos parámetros los ingresamos en el campo “Raw Query parameters” y lanzamos una búsqueda general con q = “*:*”
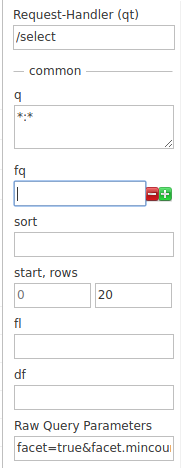
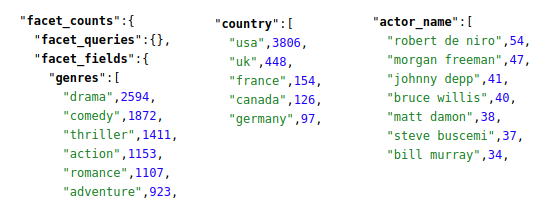
Si vamos al final de la página de resultados, veremos los resultado por faceta:
Y si filtramos con fq (filter query) por el género de acción, fq = genres:”action”, añadimos el filtro tal y como se muestra en la siguiente imagen:
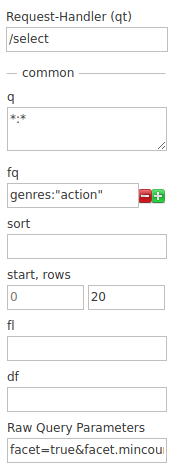
Las facetas tendrán los siguientes resultados:
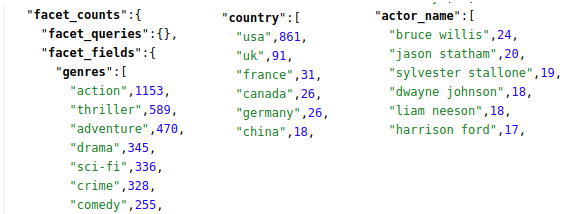
Si nos fijamos en la cantidad de documentos para la faceta “action”, 1153, veremos que coincide con los resultados al filtrar el contenido por el género acción:
![]()
Y esto será todo lo que veremos en este tutorial de Apache SOLR. Si te interesa mantener los cambios y seguir investigando, puedes detener el contenedor usando: docker-compose stop
Para volver a levantar el contenedor: docker-compose start
Si queremos eliminar el entorno, y no tenemos otras imágenes ni contenedores, podemos lanzar un: docker-compose down –rmi local -v
Si tenemos otros contenedores e imágenes además de la de SOLR, podemos eliminarlos manualmente, primero el contenedor y luego la imágen:
docker container rm <nombre_del_contenedor_solr> docker image rm <nombre_de_la_imagen_solr>
Lo que hemos visto en este tutorial de Apache SOLR
- Hemos visto cómo utilizar Docker como herramienta para levantar un contenedor y trabajar en local.
- También cómo utilizar una configuración base para crear un core (índice).
- Así mismo, hemos explicado cómo crear un schema y campos personalizados analizando previamente la fuente de datos a indexar.
- Y cómo enviar documentos para que SOLR indexe el contenido.
- Y por último hemos visto cómo realizar búsquedas básicas y facetado de los resultados devueltos por SOLR.
- En nuestro esquema no hemos definido el campo imdb_link, sin embargo, aparece en el índice. Esto se debe a que en el archivo solrconfig.xml se ha definido un updateRequestProcessorChain de nombre “add-unknown-fields-to-the-schema”, y que básicamente, se dispara al indexar/actualizar un campo y si no está definido en el esquema, trata de “adivinar” el tipo del campo y lo envía al índice.
Pero hay más, mucho más
Lo que no hemos visto:
- Cómo utilizar los query parsers para realizar búsquedas con mayor precisión y realizar queries más complejas: disMax y edisMax.
- Campos dinámicos.
- DIHs – Data Import Handlers.
- Boosting.
- RequestHandlers, todos los parámetros que pasamos a través de una query al realizar búsquedas, se pueden configurar en un requestHandler dentro del archivo solrconfig.xml.
- Spatial Search.
- El framework CELL para extracción e indexación de contenido de documentos DOC, PDF y HTML.
- Los componentes:
- QueryElevation.
- Suggester.
- Highligting.
- SOLRCloud.
Cerrando…
Apache SOLR es una herramienta potente para crear buscadores de contenido, es bastante extenso y sin experiencia previa, resulta difícil incluso llegar a la fase de indexación de contenido. Espero que este post te haya dado un buen punto de partida.
¡Hasta la próxima!
1 Comentario
¿Por qué no comentas tú también?
Muchas gracias por compartir tus conocimientos, por favor sigue compartiendo tus conocimientos de Apache Solr.
harry izquierdo Hace 8 años
Queremos tu opinión :)