¡Muy buenas a tod@s!
Hoy nos toca un término medio entre ingeniería de sistemas y soluciones de VozIP SIP :).
Nos queremos centrar en algo que de forma burda se resumiría de la siguiente manera: «Hola Ingenieros de Voz y Sistemas, es súper importante que sepáis que no quiero perder ni una sola llamada en curso, me vale una mini pérdida de audio, pero que no se caigan las llamadas, mi entorno es absolutamente crítico«.
La verdad es que es un requisito que tiene su razón de ser en muchos casos: sistemas de interfonía en infraestructuras de transporte, en plantas de producción como mecanismos de emergencia, en sistemas de radio integrados con VoIP, etc… Una serie de desarrollos que ponen de relieve necesidades emergentes como la base para tener la HA mínimamente viable:
- Fence Agents (Regletas gestionables, sistemas IPMI / iDRAC / ILO)
- Es decir: Poder reiniciar eléctricamente un nodo vía STONITH en caso de discrepancias en el cluster.
- Redes físicas redundadas (Corosync RRP – Redundant Ring Protocol)
- Para tener un camino alternativo de control totalmente aislado del otro.
- No tiene porque ser ethernet, puede ser CSLIP con un cable null-modem entre servidores.
- Enlaces a cada red redundados (LACP o similar)
Asumiendo que tenemos todo eso, dentro del ámbito SIP y Open Source, se nos presentan varias tecnologías candidatas para conseguir el 0,000 call tear down, asumiendo que queremos tener un control de diálogos activos (limitación de canales, BLF’s vía PUA …) :
- Con OpenSIPS lo podríamos hacer con el módulo clusterer y el módulo dialog —para la parte señalización—.
- Con Kamailio la opción sería usar el módulo DMQ, y el módulo tb dialog para la parte señalización.
- En ambos casos, el único candidato de proxy rtp que sería compatible con un escenario de full HA sin tirar llamadas es RTPEngine, junto con su soporte para REDIS.
En lo referente a tecnologías de Proxy SIP y media services, para la parte de HA nos quedaremos con nuestra querida pareja de Pacemaker y Corosync.
Dibujando el escenario
Básicamente, este sería nuestro objetivo final. Esta pieza en el puzzle de una arquitectura grande:
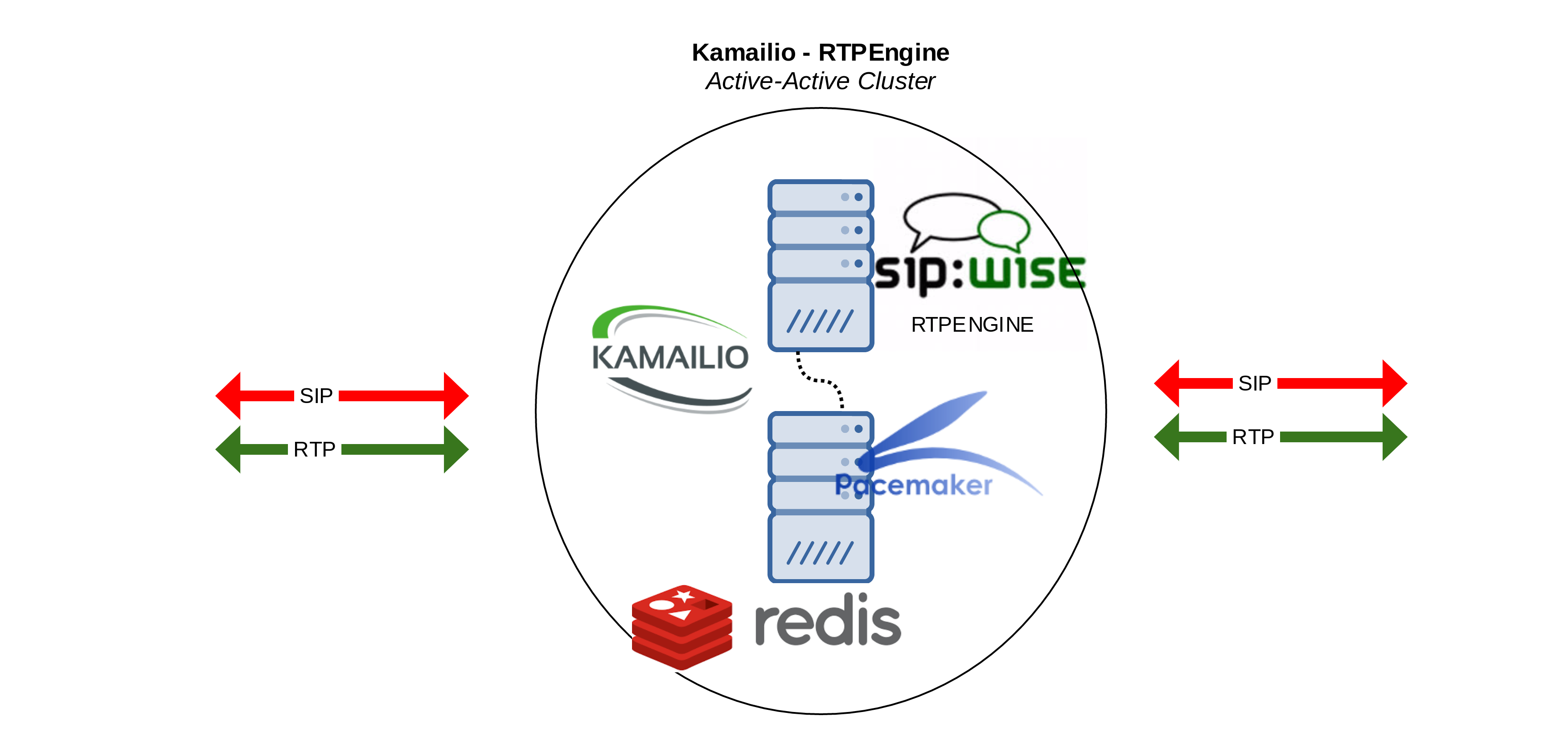
Primer paso: Kamailio, RTPEngine, Redis
En esta primera parte, dejaremos instalado y probado el trío, para validar que las sesiones se cursan y se guardan en REDIS correctamente.
Redis
Por el momento, no necesitamos una instalación compleja. Se trata de ilustrar pruebas, así que fine tuning / security policies quedan fuera del alcance. Sí que tendremos en cuenta la parte de Master/Slave que veremos en la siguiente sección principal, una vez el trío inicial esté UP&Running.
RTPEngine
Gracias al maravilloso sistema de instalación basado en paquetes Debian (dpkg-buildpackage) por Victor Seva, la instalación es casi trivial en un host con Debian standard de cara al arranque. Por el momento para este ejemplo sin systemd:
/usr/sbin/rtpengine --interface=10.10.0.142 \ --listen-ng=10.10.0.142:2223 --tos=184 \ --redis 10.10.0.144:6379/0 \ --pidfile=/var/run/rtpengine01.pid
Donde:
- listen-ng es donde queremos que escuche a nivel de control el RTPEngine.
- redis es el servidor redis (al no usar -w será el servidor de lectura/escritura el mismo).
- interface es la IP donde queremos que gestione el media.
Esto sería todo para tener la base funcionando, también sin entrar en detalles de kernel level proxying para rendimiento ni nada.
Kamailio
En el caso de Kamailio, aparte de tener el módulo de RTPEngine cargado:
loadmodule "rtpengine.so"
Y configurado:
modparam("rtpengine", "rtpengine_sock","udp:10.10.0.142:2223=1")
Tenemos que realizar las llamadas correctas a rtpengine_offer y rtpengine_answer, o agruparlo en rtpengine_manage —y fin—.
Hay que tener en cuenta que es necesario acordarse de hacerlo tanto en las request route como on reply route, para gestionar también correctamente el 200 OK enviado por el destino.
Llamadas de prueba
En este punto, poco más que comentar que no se explique perfectamente en un shot de sngrep:
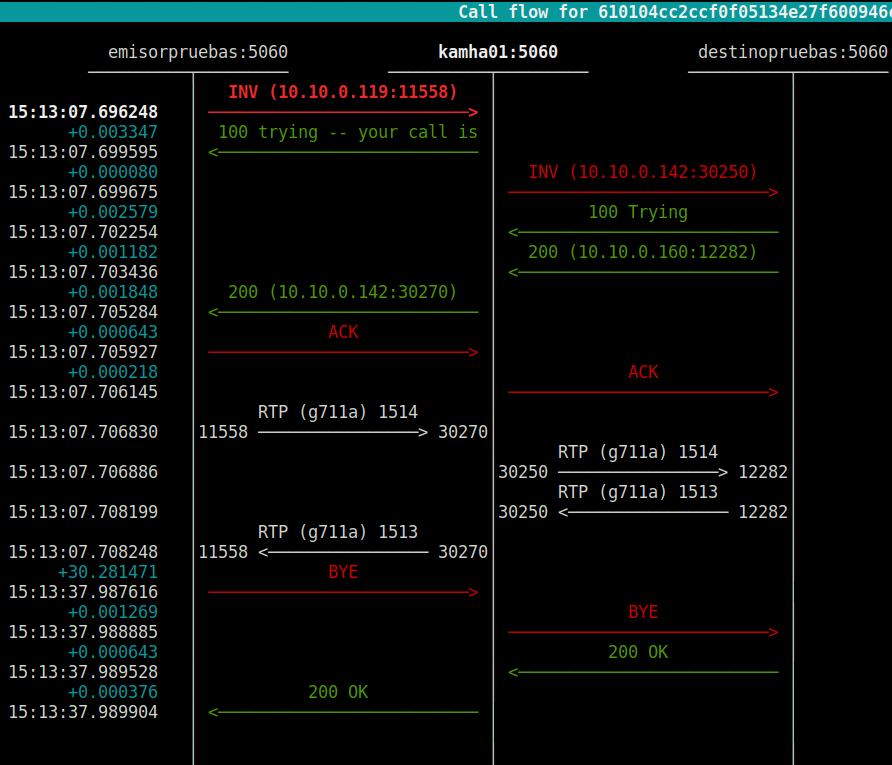
Es decir, kamha01 recibe/envía el audio de ambos interlocutores (emisorpruebas y destinopruebas). De hecho, coinciden los contadores de paquetes 😉 que casan también con los logs de RTPEngine:
Final packet stats: --- Tag 'as1f242a23', created 1:00 ago for branch '', in dialogue with 'as351607bf' ------ Media #1 (audio over RTP/AVP) using PCMA/8000 --------- Port 10.10.0.142:30270 <> 10.10.0.119:11558, 1514 p, 260408 b, 0 e, 1488291217 last_packet --------- Port 10.10.0.142:30271 <> 10.10.0.119:11559 (RTCP), 6 p, 384 b, 0 e, 1488291217 last_packet --- Tag 'as351607bf', created 1:00 ago for branch '', in dialogue with 'as1f242a23' ------ Media #1 (audio over RTP/AVP) using PCMA/8000 --------- Port 10.10.0.142:30250 <> 10.10.0.160:12282, 1513 p, 260236 b, 0 e, 1488291217 last_packet --------- Port 10.10.0.142:30251 <> 10.10.0.160:12283 (RTCP), 6 p, 384 b, 0 e, 1488291217 last_packet
Si de mientras estamos en el CLI de Redis, podemos validar igualmente que se escribe la key de la sesión correctamente:
# redis-cli -h 10.10.0.144 10.10.0.144:6379> keys * 1) "[email protected]:5060"
Igualmente, con Redis Desktop Manager también se ven de forma muy gráfica las sesiones activas:
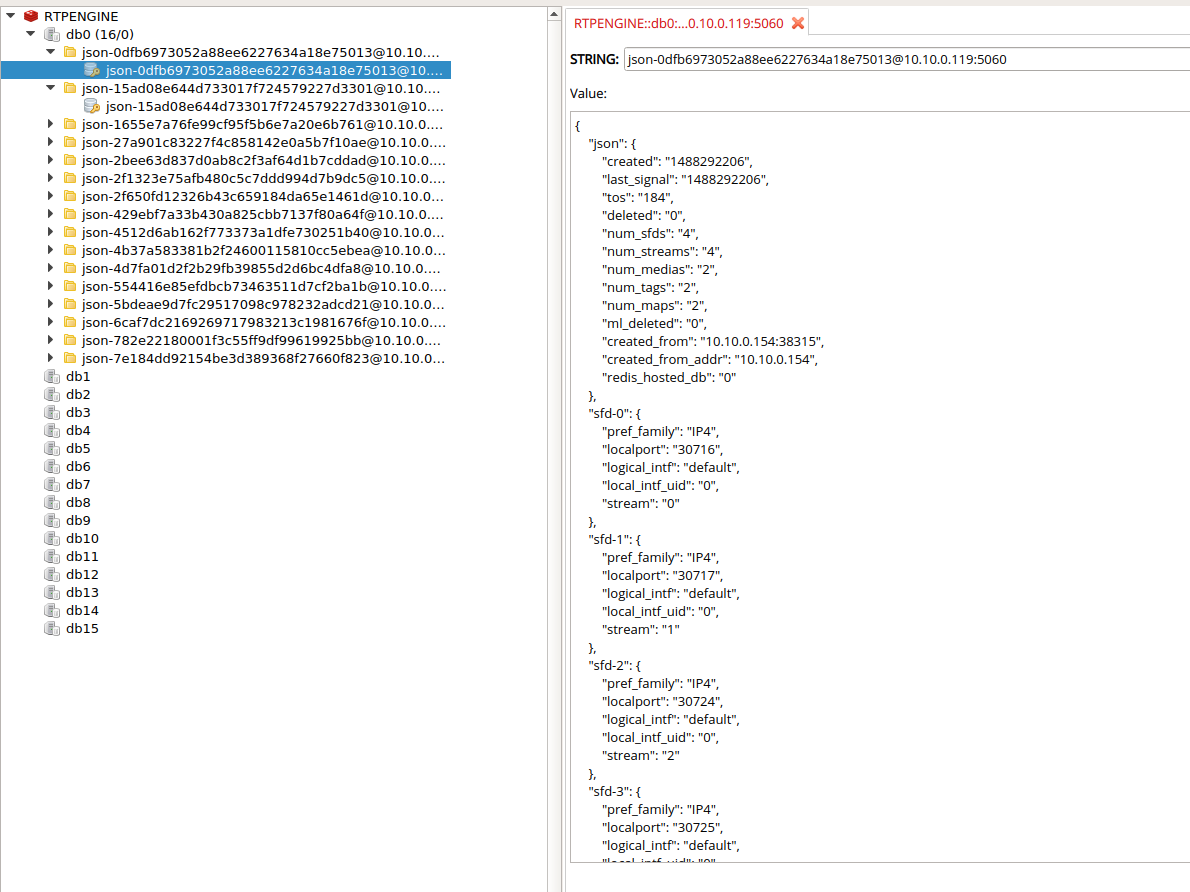
Para más información sobre la estructura https://github.com/sipwise/rtpengine/wiki/Redis-data-structure
Resumiendo
En este punto, no es que tengamos nada especialmente complicado. Sin HA, se trata únicamente de un proxy sip que usa RTPEngine, que a su vez escribe sus sesiones en REDIS.
Construyendo el escenario HA
TIP: Non Local BInd
Esta es una opción que de vez en cuando simplifica muchísimo el escenario:
# cat /etc/sysctl.conf | grep -i non net.ipv4.ip_nonlocal_bind=1
Esto nos permite tener por ejemplo Kamailio con un listen específico a dicha IP, aunque no la tenga en ninguna de sus interfaces. De dicha forma, se desacopla totalmente la secuencia de «Levantar IP Virtual => Arrancar servicio».
Es decir, nos tenemos que preocupar únicamente de garantizar que la IP Virtual esté en al menos alguno de sus nodos.
Tecnología de Cluster: Pacemaker / Corosync
La verdad es que Pacemaker es siempre nuestro gran aliado cuando se trata de sistemas GNU/Linux y alta disponibilidad, siendo Corosync su capa de comunicación. El resto de componentes —Resource Agents, etc— se ilustran bien en esta imagen cogida de Clusterlabs.org :
En cuanto a datos para ilustrar este ejemplo que estamos montando:
- 10.10.0.142: Será la primera IP Virtual.
- 10.10.0.143: Será la segunda IP Virtual del cluster Active Active de Kamailio/RTPEngine.
- 10.10.0.144: Será la IP de HA dónde siempre esté el Master REDIS.
Redis Master-Slave Cruzado
Esto, al igual que MySQL, basta con cruzarlo:
- Server01:
root@zgorkamailiodmq01:~# cat /etc/redis/redis.conf | grep -i slaveof slaveof 10.10.0.172 6379
- Server02:
root@zgorkamailiodmq02:~# cat /etc/redis/redis.conf | grep -i slaveof slaveof 10.10.0.154 6379
Kamailio
En Kamailio, poco que comentar salvo que ambos añadimos el listen a las dos IP’s virtuales:
listen=udp:10.10.0.142:5060 listen=udp:10.10.0.143:5060
Recordemos que aunque no tengamos la IP como alias, no pasa nada, arrancará y lo veremos con netstat -ulnp sin problema alguno.
RTPEngine (systemd)
Para hacerlo sencillo, creamos vía systemd slices el parámetro de la IP. Así luego es muy fácil arrancarlo vía Resource Agents:
root@zgorkamailiodmq02:~# cat /etc/systemd/system/[email protected] [Unit] Description=RTPEngine [Service] EnvironmentFile=/etc/default/rtpengine ExecStart=/usr/sbin/rtpengine --interface=%i --listen-ng=%i:2223 --tos=184 --redis $REDISMASTER -f root@zgorkamailiodmq02:~# cat /etc/default/rtpengine REDISMASTER=10.10.0.144:6379/0
Con ello, tenemos por ejemplo:
root@zgorkamailiodmq02:~# systemctl status [email protected] ● [email protected] - Cluster Controlled [email protected] Loaded: loaded (/etc/systemd/system/[email protected]; static) Drop-In: /run/systemd/system/[email protected] └─50-pacemaker.conf Active: active (running) since mar 2017-02-28 22:00:57 CET; 21min ago
Nada especialmente complejo, únicamente nos preparamos el terreno para que luego sea muy cómoda la definición en el entorno CRM de ClusterLabs.
Configuración vía CRM (Cluster Resource Manager)
Quedaría algo como esto:
node 168427674: zgorkamailiodmq01
node 168427692: zgorkamailiodmq02
primitive IPHAKAM01 IPaddr2 \
params ip=10.10.0.142 nic=eth0 cidr_netmask=24 \
meta migration-threshold=2 target-role=Started \
op monitor interval=20 timeout=60 on-fail=restart
primitive IPHAKAM02 IPaddr2 \
params ip=10.10.0.143 nic=eth0 cidr_netmask=24 \
meta migration-threshold=2 target-role=Started \
op monitor interval=20 timeout=60 on-fail=restart
primitive IPHAREDIS IPaddr2 \
params ip=10.10.0.144 nic=eth0 cidr_netmask=24 \
meta migration-threshold=2 target-role=Started
primitive KAMAILIO systemd:kamailio \
op monitor interval=30s timeout=60s on-fail=restart \
op start interval=0 timeout=30s \
op stop interval=0 timeout=30s
primitive RTPENGINE_01 systemd:[email protected] \
op monitor interval=30s timeout=60s on-fail=restart \
op start interval=0 timeout=30s \
op stop interval=0 timeout=30s
primitive RTPENGINE_02 systemd:[email protected] \
op monitor interval=30s timeout=60s on-fail=restart \
op start interval=0 timeout=30s \
op stop interval=0 timeout=30s
primitive redis redis \
meta target-role=Master is-managed=true \
op monitor interval=1s role=Master timeout=5s on-fail=restart
ms redis_clone redis \
meta notify=true is-managed=true ordered=false interleave=false globally-unique=false target-role=Started migration-threshold=1
clone CLON_KAMAILIO KAMAILIO \
meta globally-unique=false clone-max=2 clone-node-max=1 target-role=Started
colocation ipredis_on_redismaster inf: IPHAREDIS redis_clone:Master
colocation rtpengine01_on_iphakam01 inf: RTPENGINE_01 IPHAKAM01
colocation rtpengine01_on_iphakam02 inf: RTPENGINE_02 IPHAKAM02
De esta configuración, cabe destacar únicamente:
- Los resources de IPHA son para las 3 IP’s virtuales (las dos para Kamailios y la de HA Redis).
- El ms redis_clone es un master/slave set.
- Con la regla de colocation hacemos que la IP de HAREDIS y el MASTER de Redis estén sí o sí en la misma máquina.
- Lo mismo con RTPENGINE01 y la IP HA 01, así como RTPENGINE02 y la IP HA 02.
- Porque aunque teóricamente puede arrancar por el non local bind, si no recibe el tráfico, poco podemos hacer 😉
- Kamailio es un clon, y no le ponemos ninguna regla de colocation, estará arrancado en ambos, ¡activo-activo!
Un vistazo rápido por el status del clúster:
root@zgorkamailiodmq01:~# crm_mon -1
Stack: corosync
Current DC: zgorkamailiodmq01 (version 1.1.15-e174ec8) - partition with quorum
Last updated: Tue Feb 28 16:47:13 2017 Last change: Tue Feb 28 16:47:04 2017 by root via cibadmin on zgorkamailiodmq01
2 nodes and 9 resources configured
Online: [ zgorkamailiodmq01 zgorkamailiodmq02 ]
IPHAKAM01 (ocf::heartbeat:IPaddr2): Started zgorkamailiodmq01
IPHAKAM02 (ocf::heartbeat:IPaddr2): Started zgorkamailiodmq02
IPHAREDIS (ocf::heartbeat:IPaddr2): Started zgorkamailiodmq01
Master/Slave Set: redis_clone [redis]
Masters: [ zgorkamailiodmq01 ]
Slaves: [ zgorkamailiodmq02 ]
RTPENGINE_01 (systemd:[email protected]): Started zgorkamailiodmq01
RTPENGINE_02 (systemd:[email protected]): Started zgorkamailiodmq02
Clone Set: CLON_KAMAILIO [KAMAILIO]
Started: [ zgorkamailiodmq01 zgorkamailiodmq02 ]
Primeras pruebas: Comprobación de Keys en Redis
Si lanzamos a modo de prueba unas pocas llamadas:
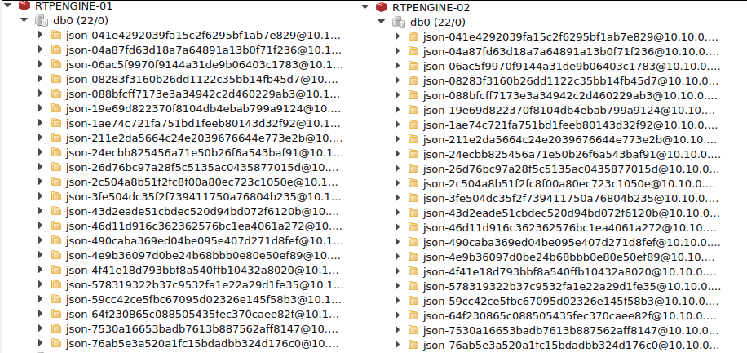
Es decir, no sólo estamos guardando las sesiones de RTPEngine en REDIS, sino que lo estamos replicando bien entre los dos servidores. De esta forma, si muere RTPEngine.
Prueba de Fuego: ¡NO tirar ninguna llamada!
Para esta primera prueba:
- Lanzamos una primera llamada pasando por el proxy 01 (junto con su RTPEngine01).
- Matamos de forma brusca la máquina.
- El clúster se da cuenta y arranca los servicios.
- IPS virtuales.
- Promociona el REDIS Server a Master.
- RTPEngine (que a su vez se conecta al Redis para conocer las sesiones vivas).
Aparte de explicar que el audio se ha perdido, pero ha vuelto al de pocos segundos, lo mejor es una captura de tráfico (on the wire is always the truth 😉 ):
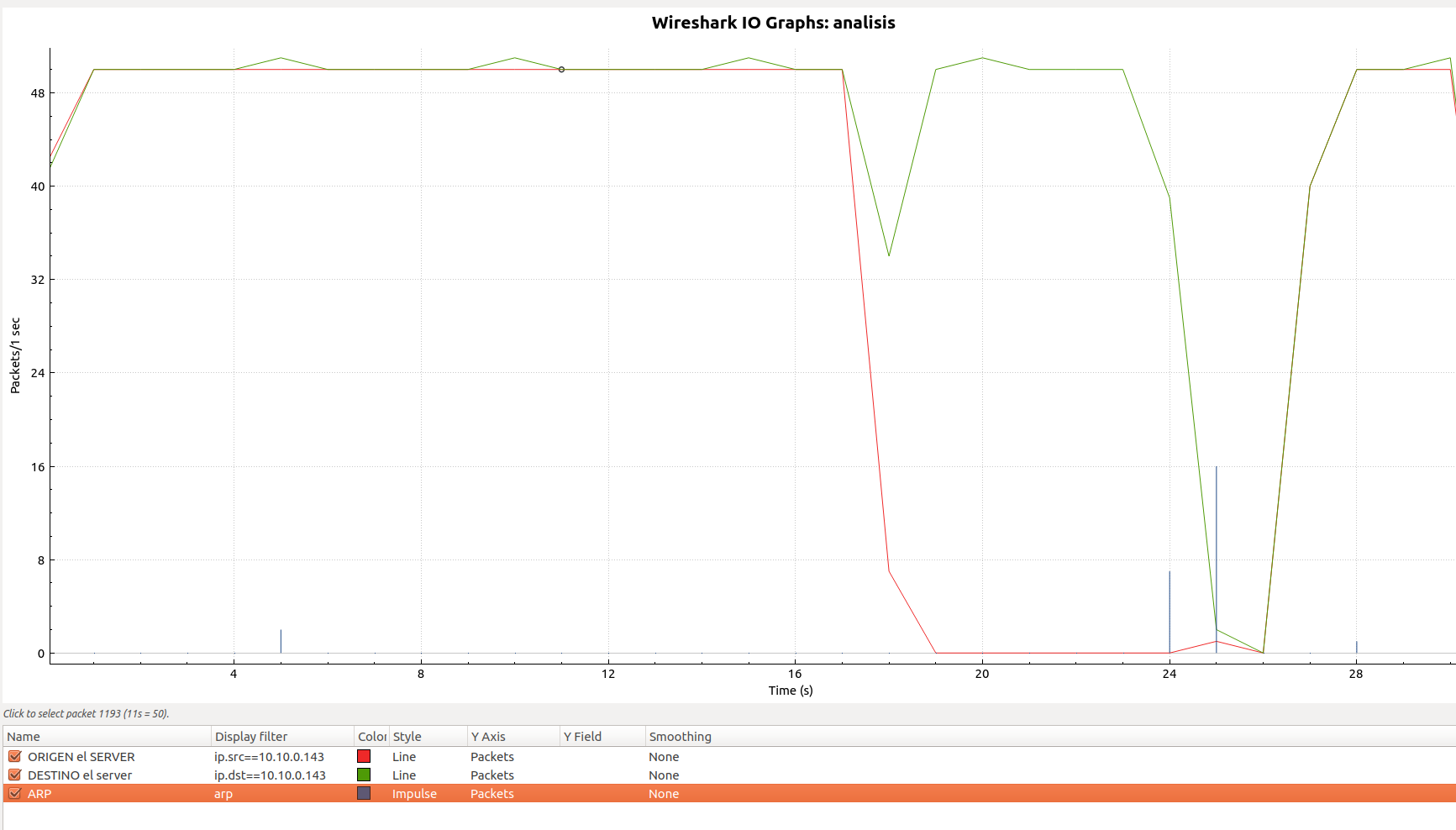
De esta captura, lo que tenemos es:
- En rojo lo que viene de RTPEngine.
- En verde lo que va hacia RTPEngine.
- En azul los momentos de ARP Requests y Gratuitous ARP Reply.
Calculando aproximadamente lo que se ve es que hemos estado unos 10/11 segundos sin audio RTP.
Puede extrañar igualmente que el audio en el otro sentido también baje, aunque esto se debe únicamente a que estamos haciendo una prueba de ECO para ver que esté todo en orden en cuanto a sesiones RTP 😉
Si cogemos la documentación de Corosync:
# How long before declaring a token lost (ms)
token: 3000
# How many token retransmits before forming a new configuration
token_retransmits_before_loss_const: 10
Por un lado, tenemos los tiempos de gestión de Pacemaker para el arranque y, por otro, la parada de servicios.
Con la configuración actual, ésta es una prueba básica desde que dispara:
Feb 28 22:00:55 zgorkamailiodmq02 crmd[696]: notice: Result of notify operation for redis on zgorkamailiodmq02: 0 (ok) [...] Feb 28 22:01:01 zgorkamailiodmq02 crmd[696]: notice: State transition S_TRANSITION_ENGINE -> S_IDLE
(Es decir, unos 6 segundos enteros en cambiar de estatus global, todo ello con las opciones default).
En cuanto al tiempo del propio RTPEngine en lo que a conectarse a Redis y recuperar las sesiones se refiere:
zgorkamailiodmq02 rtpengine[1398]: INFO: Redis restore time = 17 ms
Es decir, todo apunta a que podremos tirar del hilo, luego veremos…
Metiendo más leña a la chimenea 😉
En este caso, hemos querido probar con:
- 100-105 llamadas concurrentes.
- Codec Alaw
- Es decir, 9x 10^6 bits, unos 9Mbits sostenidos
Los resultados también son positivos, RTPEngine toma el control de los 105 streams de audio para continuar haciendo el relay en unos tiempos muy similares al caso de la prueba con una única llamada:
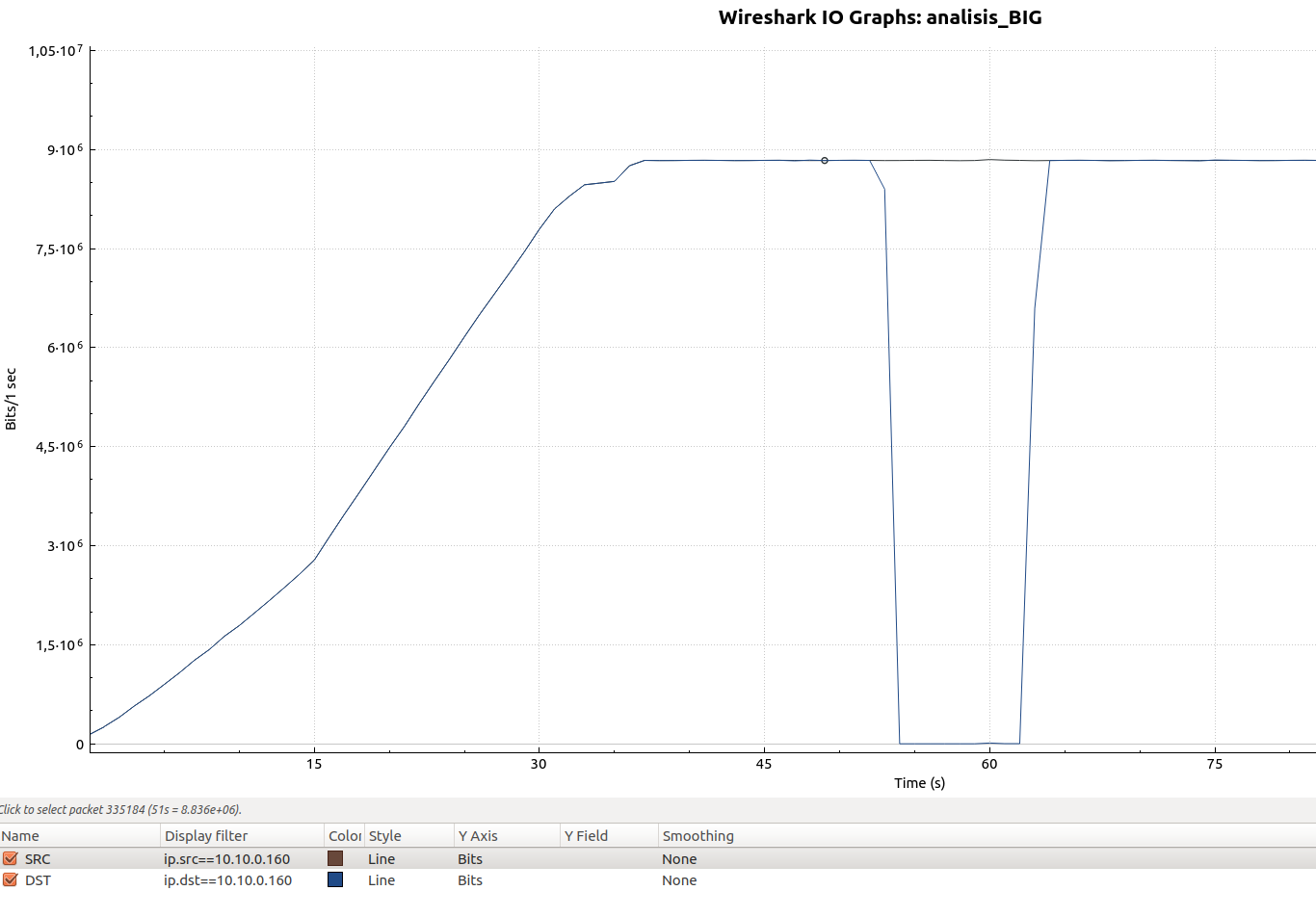
La curva inicial creciente se debe únicamente a cómo se han ido lanzado las llamadas, hasta llegar a las 100 concurrentes aproximadamente.
Objetivo final: caída no detectable por el ser humano (casi)
Es decir, queremos jugar a tener lo que sería el fuego Valyrio para la HA 😉 ¡Y no es que queramos jugar a espías ni montar IMSI Catchers con RTP re-conmutado ni nada similar!
La idea es tan simple como suena: una llamada en curso entre Alice y Bob atravesando el Proxy/Media 01, lo apagamos bruscamente y la conmutación de su conversación tiene que rozar lo indetectable.
Y aquí es cuando realmente disfrutamos de lo que hacemos y de pertenecer/aportar nuestros pequeñitos granos de arena al software open source. Es increíble lo que nos permite construir —¡sin salir ni siquiera del plano técnico!—. No dudamos de que en el caso de un sistema propietario de comunicaciones, si te compras 2 unidades enteras iguales y apagas de golpe una (no tarjetas DSP ni subpartes electrónicas), realmente puedas conseguir esto mismo. ¿O sí que dudamos;) ?
Sea como fuere, estamos listos para querer construirlo:
Teoría/Idea: Seguir aprovechando el non local bind: Hot Standby de los 2×2 RTPEngine
¿Qué nos impide tener los 2×2 RTPEngine’s arrancados?
Aunque estén arrancados, el socket de control para Kamailio nunca será accesible si no está en el nodo con la IP.
Así que podemos tenerlos en hot, esperando. En Pacemaker, plantearíamos algo tal que:
clone CLON_RTPENGINE_01 RTPENGINE_01 \
meta globally-unique=false clone-max=2 clone-node-max=1 target-role=Started
clone CLON_RTPENGINE_02 RTPENGINE_02 \
meta globally-unique=false clone-max=2 clone-node-max=1 target-role=Started
Y, obviamente, si optáramos por este camino necesitaríamos quitar las constraint de colocation que ya no necesitamos. Borramos las entradas:
colocation rtpengine01_on_iphakam01 inf: RTPENGINE_01 IPHAKAM01 colocation rtpengine01_on_iphakam02 inf: RTPENGINE_02 IPHAKAM02
De una forma más o menos resumida: estamos tendiendo hacia la estrategia de usar Clones en lugar de Primitives únicas, navegando hacia el océano Activo-Activo 😉
Sin embargo, esto que en la práctica parecería viable sin más análisis, no resulta tan simple a posteriori. Si analizamos:
- El tráfico le va llegar físicamente a un host que tiene un proceso RTPEngine que… ¡ni siquiera ha abierto ningún puerto UDP!
- Responderá con un flamante ICMP Dest Port Unreachable —y fin—.
Vamos. que por esta vía obtenemos un claro 503 a nuestra idea 😉 No víable.
Next: Bajando los tiempos default de corosync
Para empezar, nos basta con poner:
token: 50
token_retransmit: 31
hold: 31
token_retransmits_before_loss_const: 0
Es un poco arriesgado, pero recordemos el objetivo en mente: que sea casi indetectable para la especie humana.
¡Win!
Bajando los tiempos de corosync, se consigue que se pierdan escasos 20 paquetes RTP (usando un ptime standard de 20ms).
Si lo vemos analizado con nuestro querido wireshark:
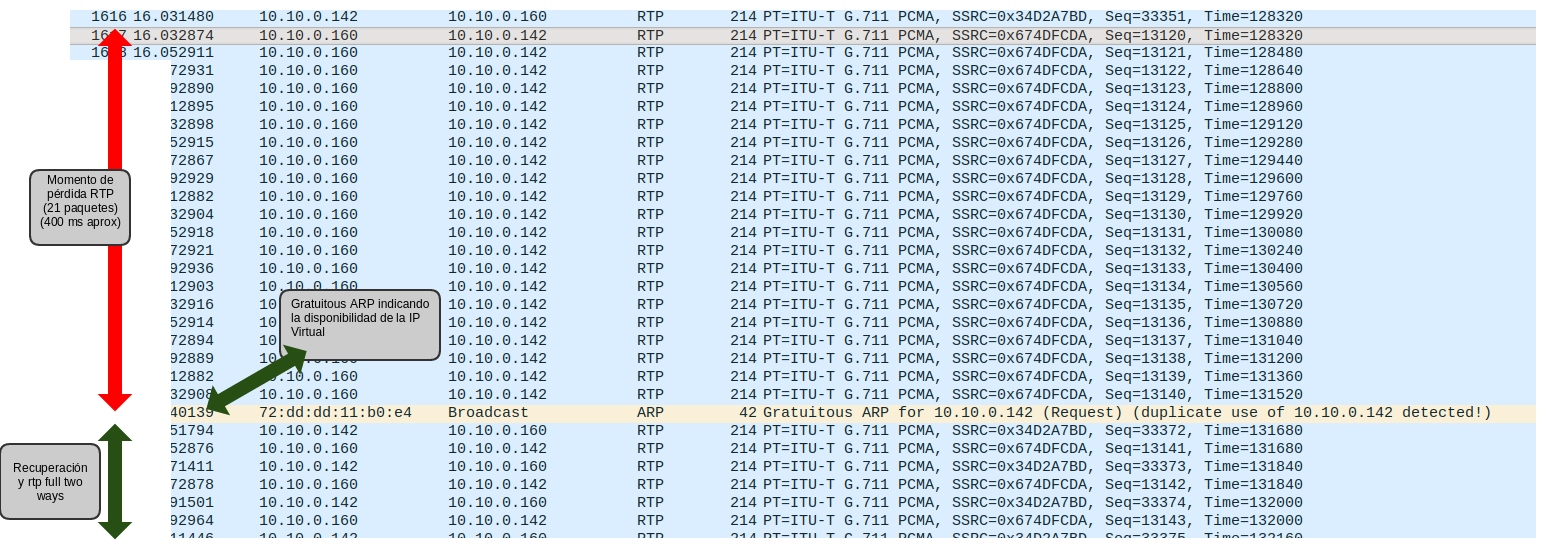
Con el mismo afán de analizar el impacto en la conversación humana, y sin tener que plantear todo un algoritmo complejo al estilo del conocido R-Factor con audacity, analizamos la grabación de ambos canales de una prueba en la que hacemos que emisor y receptor reproduzcan exactamente el mismo fichero de audio:
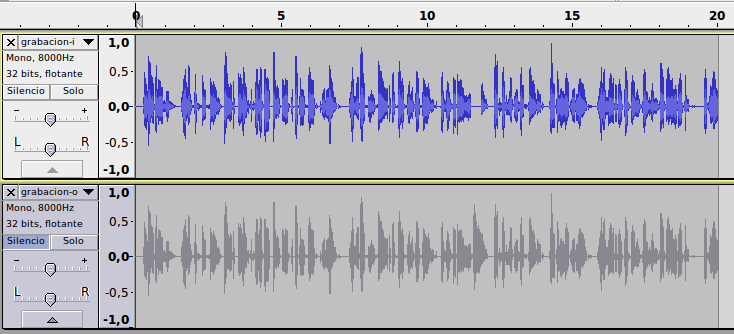
Arriba encontramos representado el audio emitido (siempre constance) y abajo el audio recibido (el que tiene la conmutación). A simple vista, parecen exactamente iguales: al ser una red de baja latencia ni vemos el offset (estamos hablando de LAN).
Sin embargo, si hacemos suficiente zoom, sí que vemos el detalle:
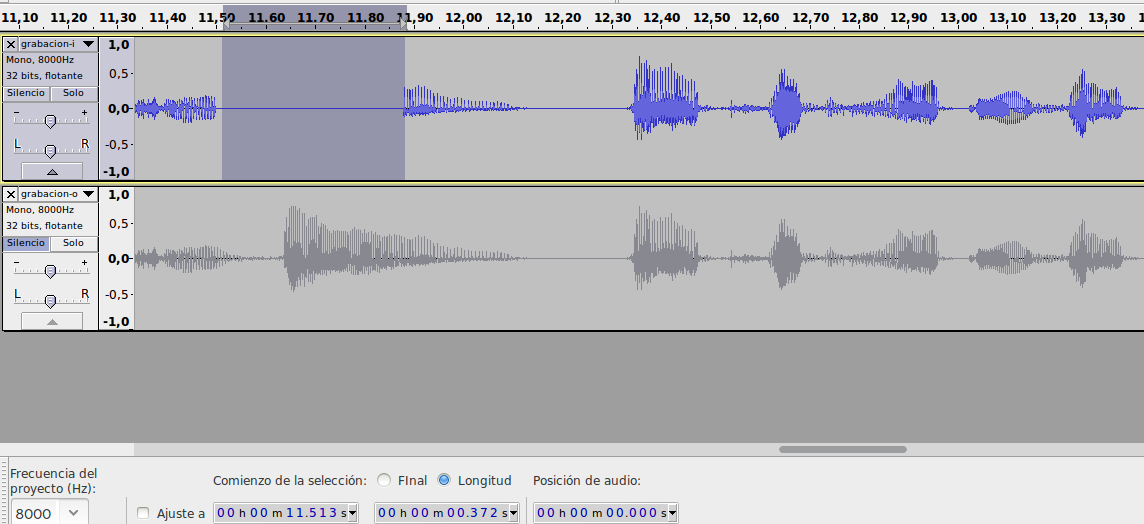
La selección muestra el momento de pérdida de audio. Contado con la propia herramienta de Audacity, nos da 372 ms de pérdida.
Si escuchamos el audio, sí que se aprecia una micro pérdida. La locución es la habitual de demo-congrats, aquí van los ficheros:
- Audio Saliente
- Audio Entrante
El gap hay que buscarlo sobre el segundo 11 🙂
La guinda para del pastel: Kamailio 5.0 y (K)DMQ !
Kamailio 5.0
Se anunciaba oficialmente el branch https://www.kamailio.org/w/2017/02/kamailio-branch-5-0-created/ indicando que quizás para finales de Febrero estaría. ¡Y así ha sido! Lo comunicaban el 27/02/217.
Tenéis toda la info en las release notes oficiales. En este post lo que nos interesa en concreto es:
- Active dialogs replication via DMQ (the Kamailio distributed message queue)
Gracias al módulo DMQ (Sipcentric LTD, Edvina AB) es perfectamente posible replicar los diálogos, con lo que todo lo que tenga que ver con conteo de canales para limitaciones o seguridad lo tenemos ya gestionado.
Es necesario activarlo:
modparam("dialog", "enable_dmq", 1)
Y gestionar la recepción on request_route:
if(is_method("KDMQ"))
{
dmq_handle_message();
}
Concluyendo …
Poco más que contar, salvo que si queréis montar esto en producción:
- Especial atención a los aspectos de seguridad para los sockets de control de RTPEngine’s.
- Todo el escenario de HA montado real (si no hay presupuesto para regletas controlables, al menos que haya IPMI para tener Fence Agents en condiciones), así como evitar Two Node Clusters 😉
Desde aquí nuestros más sinceros agradecimientos y enhorabuena al Kamailio Project y SIP Wise por poner a disposición de la comunidad estos dos excelentes proyectos.
Nada más por hoy. ¡Hasta la próxima!
1 Comentario
¿Por qué no comentas tú también?
Excelente articulo!!!
Gracias por compartir.
Saludos
Andrea Hace 9 años
Me flipa lo del microcorte RTP. Jamás me he planteado ese nivel de HA. Valiente.
Gracias por el artículo Gorka !!
Edu.
Edu Hace 9 años
Excelente artículo. Muy completo.
Aprovecho para invitaros al décimo aniversario de VOIP2DAY que se celebrará en noviembre. Os dejo la info:
En 2017, VoIP2DAY cumple 10 años (http://www.voip2day.com/es/2017) y para esta fecha tan especial hemos seleccionado un espacio novedoso y espectacular: el nuevo estadio del Atlético de Madrid, Wanda Metropolitano, que se va a convertir en un referente deportivo, social, comercial y empresarial.
Una atractiva ubicación compuesta de una zona de exposición y networking, una sala para conferencias y una terraza volada sobre la grada del Estadio ¡con unas vistas espectaculares! Además los patrocinadores dispondrán de palcos privados para realizar actividades.
El evento durará dos días y será cita obligada para el canal de comunicaciones IP en el que tendrán cabida usuarios finales, partners, resellers, integradores, operadores, fabricantes y desarrolladores. VoIP2DAY es un referente internacional en materia de comunicaciones unificadas que albergará durante dos días las últimas novedades del sector.
Rosalía Hace 9 años
Excelente gracias por el articulo.
Consulta: tienes algún how-to que explique todo paso a paso o desde cero?
Saludos
fernando Hace 8 años
Queremos tu opinión :)